|
(このコンテンツはメールマガジンの STL & iostream 入門に手を加えたものです。「 STL と iostream が使えるかのチェック」等はメールマガジンの方のページをご覧ください)
|
|
アルゴリズムとは ( #01 ) |
 STL は主に次の5つから構成されています。アルゴリズム、関数オブジェクト、イテレーター、コンテナ、サポートクラスです。この中で最も重要なのが「アルゴリズム」です。他の4つはアルゴリズムのためにある、と言っても過言ではありません。というわけで、 STL の中でもまずこのアルゴリズムから見ていくことにします。
STL は主に次の5つから構成されています。アルゴリズム、関数オブジェクト、イテレーター、コンテナ、サポートクラスです。この中で最も重要なのが「アルゴリズム」です。他の4つはアルゴリズムのためにある、と言っても過言ではありません。というわけで、 STL の中でもまずこのアルゴリズムから見ていくことにします。「アルゴリズム」という言葉は、一般的に「特定の結果を求めるための処理方法」という意味で使われています。たとえば「配列上のデータをソートする」などがアルゴリズムの一例です。 STL のアルゴリズムは、基本的に「別物」と考えた方が分かりやすいと思います。使いこなせるようになれば「ああ、アルゴリズムだ」と思うようになるかもしれませんが、当分の間は「いわゆる一般的なアルゴリズムとは違うもの」と考える方がいいと思います。 じゃあなんなのかというと、それはズバリ「 for などのループを代わりにしてくれる関数」です。 STL のアルゴリズムは、 for や while を使ったループ処理を、代わりにしてくれる関数を集めたライブラリなんです。 というわけで、試しにひとつ使ってみましょう。
/////////////////////////////
// std::fill() の使用例。
#include <stdio.h>
#include <algorithm> // をインクルードしましょう。
void Use_fill()
{
int iAry[10];
std::fill( iAry, iAry + 10, 7 );
printf( "%d\n", iAry[3] ); // 試しに3番目を出力。
}
// 結果
7
/////////////////////////////
この中で使われている std::fill() が、アルゴリズムに含まれている関数のひとつです。何をやっているか順に見ていきましょう。 まず int 型の配列を作ります。要素の数は10個です。これはなんの初期化もしていませんから、当然ゴミが入っています。 そこで出てくるのが std::fill() です。この関数は「配列の全要素に特定の値を代入する」という仕事をしてくれます。ここでは、直前に作った配列の全要素に、 7 という数字を代入しています。つまり、 std::fill() を呼んだこの1行だけで、 iAry の初期化が完了したということです。 最後は試しに3番目の要素だけ出力してみたものです。もちろんすべての要素に 7 が入っています。 |
|
|
std::fill() をもう少し詳しく見てみましょう。この関数の引数は3つ。次のようになっています。
std::fill
( iAry // 1: 開始位置へのポインタ。
, iAry + 10 // 2: 終了位置+1へのポインタ。
, 7 ); // 3: 代入する値。
 std::fill() は、「第1引数から第2引数−1までの各要素に第3引数を代入する」という仕様になっています。
std::fill() は、「第1引数から第2引数−1までの各要素に第3引数を代入する」という仕様になっています。通常は、第1引数には「配列の先頭ポインタ」を、第2引数には「配列の先頭ポインタ+全要素数」を渡します。この「全要素数」が使えるように、第2引数は「終了位置+1」を受け取る仕様になっています。これはアルゴリズム全体の仕様です。 さらに、 std::fill() の中身について見てみましょう。 std::fill() は、呼ばれたときこんな感じの実装になっています。
void fill
( int *p_pBegin
, int *p_pEnd
, const int &p_rValue )
{
for( ; p_pBegin != p_pEnd; ++p_pBegin )
*p_pBegin = p_rValue;
}
配列へは、 for ループとポインタを使って値を埋めていきます。 第1引数の「配列の先頭ポインタ」は、第3引数を入れてはインクリメントする、ということの繰り返しを for ループで行われます。そして、インクリメントされたポインタが第2引数の「終了位置」と同じになったら for ループを終了させ、関数が終了します(なので「終了位置」には値が入らない仕組みになっています)。 このように、 for ループを使った思いっきりべたべたな方法で、配列の各要素に値を入れています。 このようにアルゴリズムは、単に「 for ループを代わりにしてくれる」 だけの機能です。 |
|
置き換える意味 ( #02 ) |
|
先ほど説明したように、 STL のアルゴリズムは「 for などを関数に置き換える」という機能を持っています。
ということは、逆に「 STL アルゴリズムは for などに置き換えられる」ということも言えます。そこで、前回の Use_fill() を、 for ループを使用したプログラムへと書き換えてみましょう。
////////////////////////////////////////////////////////////////
// std::fill() を for に置き換えた例。
void Use_fill_origigal()
{
int iAry[10];
for( int *piAry = iAry; piAry != iAry + 10; ++piAry )
*piAry = 7;
printf( "%d\n", iAry[3] ); // 試しに3番目を出力。
}
// 結果
7
/////////////////////////////
なんと、 std::fill() を使ったときに比べてたった1行増えただけです。 STL アルゴリズムは、コードの簡略化にはあまり役だってないようです。ではなぜ、わざわざ STL アルゴリズムを使用する必要があるのでしょうか。 それは「解りやすい」からです。 注目点となっている件の2行を抜き出してみましょう。 for( int *piAry = iAry; piAry != iAry + 10; ++piAry ) *piAry = 7; これが STL アルゴリズムを使うことで次の1行へと置き換えられます。 std::fill( iAry, iAry + 10, 7 ); for ループが実際に何をしているかは、 for で使用されている各変数を調べ、そしてループの中身を見なければなりません。 対して、 fill という英単語はよく知られているように「何かを満たす」という意味があります。 std::fill() という関数名だけで「 iAry が特定の値で満たされる」ということが一目瞭然です。さらに付け加えるのなら、std::fill() は標準 C++ ライブラリの関数のひとつなのだから、多くの C++ プログラマーが知っている(はず)ということでもあるのです。 つまり、プログラムとして、 std::fill() を使った方が断然読みやすく解りやすい! ということなのです。 ……それがなんでいいの? と思った方には、おそらく STL は全然「いいもの」には見えないと思います。 STL の魅力のひとつは「可読性を高める」という点があります。 STL が理解されない、使いこなすのが難しい、と言われるのは、こういった「これまでと違う思想」が入っているからじゃないかなと思います。 「この思想に染まってみませんか?」とは口が裂けても言えません。この思想は、 C++ でしか通用しないのですから。 さて話を戻しましょう。 std::fill() に置き換えるメリットをもうひとつ挙げるとすれば、それは for に使用する変数関係の面倒さでしょう。 for の小カッコの中で、変数の初期化や比較、インクリメントを行っています。 std::fill() は、これをひとつの関数に封じ込めているというわけです。 なぜ封じ込めるのかというと、それは std::fill() は「テンプレート」として作られているからです。例えば、次のプログラムを見てください
////////////////////////////////////////////////////////////////
// std::fill() の使用例、 double 編。
#include <stdio.h>
#include <algorithm>
void Use_fill_d()
{
double dAry[10]; // double です。
std::fill( dAry, dAry + 10, 7.3 );
printf( "%f\n", dAry[3] ); // 試しに3番目を出力。
}
// 結果
7.300000
/////////////////////////////
このように、 double の配列でも同じように std::fill() に渡すことができます。これがテンプレートとして std::fill() が作られている理由です。関数テンプレートなので、たいがいの配列を受け取ることができるのです。 |
|
|
std::fill() の機能は「配列を特定の値で埋める」というものです。これは「 for を配列を埋めるという機能に特化した」と言うことができます。 for を使ってできる機能のひとつを、関数に封じ込めたというわけです。逆に言えば、 std::fill() にはそれ以外の機能はありません。
それ以外の機能を使うにはどうすればいいのか? それは、他の STL アルゴリズム関数を使えばいいのです。次はそれを紹介しましょう。 |
|
アルゴリズム・配列ひとつ編 ( #03 ) |
|
アルゴリズムは STL の根幹と言えるだけあって、かなりの数が用意されています。ここですべてを紹介することはやめておいて、分類別に使い方等を見ていくことにしましょう。
まずは「ひとつの配列を受け取るもの」から。
////////////////////////////////////////////////////////////////
// std::reverse の使用例。
#include <stdio.h>
#include <algorithm>
void Use_reverse()
{
int iAry[] = { 3, 5, 1, 6, 3, 1 };
std::reverse( iAry, iAry + 6 );
for( int *pi = iAry; pi != iAry + 6; ++pi )
printf( "%d, ", *pi );
}
// 結果
1, 3, 6, 1, 5, 3,
/////////////////////////////
std::reverse() は「配列を前後逆にする」というアルゴリズムです。 このアルゴリズムや、前回の std::fill() などは、配列をひとつだけ受け取って、その配列にアルゴリズムの結果を格納します。「どこからどこまで」の指定が std::fill() と同じことを確認しておいてください。 もうひとつ、 std::find() の例を見てみましょう。
////////////////////////////////////////////////////////////////
// std::find() の使用例。
#include <stdio.h>
#include <algorithm>
void Use_find()
{
int iAry[] = { 3, 5, 1, 6, 3, 1 };
int *piThis = std::find( iAry, iAry + 6, 1 );
if( piThis != iAry + 6 )
printf( "%d\n", *piThis );
}
// 結果
1
/////////////////////////////
std::find() は、第3引数と同じ値の要素を探して、あればその要素を指すポインタを返します。見つからなければ第2引数を返すので、それをちゃんとチェックしておきます。このような「検索系」アルゴリズムはどれも似たような仕様になっています。 また、このアルゴリズムのように、渡した配列に必ずしも値が書き込まれるとは限りません。この辺はアルゴリズムによって変わってきます。 配列をひとつ受け取るアルゴリズムの中に、ちょっと違う種類のものがあります。 std::fill_n() などの、関数名に _n が付くアルゴリズムです。
////////////////////////////////////////////////////////////////
// std::fill_n() の使用例。
#include <stdio.h>
#include <algorithm>
void Use_fill_n()
{
int iAry[10];
std::fill_n( iAry, 10, 7 ); // ここで使ってます。
for( int *pi = iAry; pi != iAry + 10; ++pi )
printf( "%d, ", *pi );
}
// 結果
7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
/////////////////////////////
std::fill_n() は、他のアルゴリズムと違って「指定された数だけ」処理をします。 他のアルゴリズムで「どの要素まで処理するか」を指定する時は「配列の先頭ポインタ+要素数」、つまり「最後の要素インデックス+1のポインタ」を渡していました。 ところが、 std::fill_n() は「要素数」です。つまり、ポインタではないということです。 std::fill_n() の他に std::search_n() など、少数ですがこのタイプのアルゴリズムが用意されています。 「なんでこんなのが必要なの?」ということの答は、もう少し先、渡すポインタが本当は「イテレーター」と呼ばれるものなんだ、ということが分かってからになると思うので、今は「こういうものがあるんだ」ということで頭の片隅にでもとどめておいてください。 「配列をひとつ受け取るアルゴリズム」は、アルゴリズムの中でも最も多くの関数テンプレートが用意されています。リファレンスなどを参考にして「どんなときにどんなアルゴリズムが使えそうか」頭の中に入れておくといいでしょう。 |
|
アルゴリズム・配列ふたつ&みっつ編 ( #04 ) |
|
次は「ふたつの配列を受け取るアルゴリズム」について見ていきます。この種類のアルゴリズムは「ある配列をコピーする」とか「配列と配列を比較する」などの機能が中心です。
実際に「コピー」してみましょう。コピーには std::copy() を使います。
////////////////////////////////////////////////////////////////
// std::copy() の使用例。
#include <stdio.h>
#include <algorithm>
void Use_copy()
{
int iSourceAry[] = { 3, 5, 1, 6, 3, 1 };
int iAry[6];
std::copy( iSourceAry, iSourceAry + 6, iAry ); // ここで使用。
for( int *pi = iAry; pi != iAry + 6; ++pi )
printf( "%d, ", *pi );
}
// 結果
3, 5, 1, 6, 3, 1,
/////////////////////////////
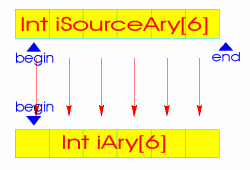 std::copy() は、第1引数から第2引数までの範囲を第3引数へとコピーします。実際には、各要素をそのまま代入しているだけです。
std::copy() は、第1引数から第2引数までの範囲を第3引数へとコピーします。実際には、各要素をそのまま代入しているだけです。std::copy() を使う上での注意点を見てみましょう。 コピーは「左から右へ」行われます。第1引数と第2引数がコピー元で、第3引数がコピー先です。 strcpy() などとは逆ということに注意してください。 第3引数は「配列の先頭」だけを渡していることに注意してください。つまり、この「コピー先」となる配列に十分なサイズが確保されていない場合、あっさりとオーバーランします。実際にはアルゴリズムに渡す前に「サイズが十分か」チェックする必要があります。 最後に「渡す配列の型」について。第1・2引数と第3引数は、別の型を指定できます。コピー元は double の配列、なんてこともできます。 特に重要なのが「オーバーラン」の問題でしょう。この部分は致命的なバグになりかねません。必ずチェックするようにしましょう。 アルゴリズムにはあと「配列をみっつ受け取るもの」があります。この例も見てみましょう。
////////////////////////////////////////////////////////////////
// std::merge() の使用例。
#include <stdio.h>
#include <algorithm>
void Use_merge()
{
int iSourceAry1[] = { 1, 2, 3, 4, 5, 6 };
int iSourceAry2[] = { 7, 8, 9, 10 };
int iAry[10];
std::merge
( iSourceAry1, iSourceAry1 + 6
, iSourceAry2, iSourceAry2 + 4
, iAry );
for( int *pi = iAry; pi != iAry + 10; ++pi )
printf( "%d, ", *pi );
}
// 結果
1, 2, 3, 4, 5, 6, 7, 8, 9, 10,
/////////////////////////////
std::merge() は、第1・2引数と第3・4引数の要素をあわせて第5引数へとコピーするアルゴリズムです。ほとんど std::copy() と同じですね。違うのは「配列の数がみっつ」というくらいです。書き込む配列のサイズが十分にあることなど、注意点も同様のことが言えます。 ここまで、少ないながらも様々な種類のアルゴリズムを見てきました。ですが、おそらく皆さんは「どれも似てる」と感じることでしょう。それは別に似ているアルゴリズムを集めたわけではなくて、どのアルゴリズムも実際に似ているからです。 と言っても、実際に行っていることはそれぞれのアルゴリズムで大きく違います。 std::fill() と std::count() は、渡す引数などは同じですが、その中身は「値を埋める」のと「値を数える」と、大きく違います。似ているのは、引数の呼び出し方だけです。 これが実は、非常に大事なことなのです。 STL アルゴリズムは、どれも似たような形で引数を受け取ります。これはつまり、配列に対する操作はどれも同じということです。この「同じ」という点と、分かりやすい関数名から、そのアルゴリズムが実際にどのようなことを行うのか、簡単に想像できます。 これも、プログラムの「可読性」を高めてくれるというわけです。 |
|
アルゴリズムを作ろう! ( #05 ) |
|
前述の「アルゴリズム・配列ひとつ編」と「ふたつ編」で、何度も次のような2行が出てきました。
for( int *pi = iAry; pi != iAry + 10; ++pi )
printf( "%d, ", *pi );
配列の全要素を出力する for ループです。 #01 を読んだ方は、この for ループがアルゴリズムの中身で使われている for の形式に似ていることに気付いたことでしょう。そして思うはずです。「この for ループ、アルゴリズムにできないのかな?」と。 というわけで、この「 printf() で出力するアルゴリズム」を作ってみましょう。STL の魅力のひとつは「ないものは自分で作る」ということが簡単にできるという点です。 まず、普通の関数として作ってみましょう。関数テンプレートとしていきなり作ろうとするよりも、まず普通の関数として作った方が失敗が少ないと思います。 受け取る配列は int 型としましょう。他のアルゴリズムと同じように「最初」と「最後+1」を受け取るようにします。あと、 printf() は出力する型を "%d" などの形で指定しなければならないので、この文字列も受け取るようにしましょう(「 std::strstream なら必要ないのに」と思った方、その想いは近いうちにかなえられることでしょう)。 そうすると、こんな感じになります。
// printf() アルゴリズムのテスト関数。
void Alg_printf_0
( int *p_piBegin
, int *p_piEnd
, const char *const p_pchFormat )
{
for( ; p_piBegin != p_piEnd; ++p_piBegin )
printf( p_pchFormat, *p_piBegin );
}
中の for が std::fill() とほとんど同じことを確認してください。これが、アルゴリズムのもっとも基本的な形です。引数はポインタにしておきます。こうすることで配列を受け取れます。 この関数の使用例はこんな感じになります。
////////////////////////////////////////////////////////////////
// Alg_printf_0() の使用例。
void Use_Alg_printf_0()
{
int iAry[] = { 3, 5, 1, 6, 3, 1 };
Alg_printf_0( iAry, iAry + 6, "%d, " );
}
// 結果
3, 5, 1, 6, 3, 1,
/////////////////////////////
引数の渡し方など、いかにもアルゴリズムっぽいですね。これで第1段階はクリアです。 次にこの関数をテンプレート化します。そうしないと、 int 型配列以外を渡すことができないからです。 関数テンプレート化すると、次のようになります。
// printf() アルゴリズム。
template< class type_Ary >
void Alg_printf
( type_Ary p_pBegin
, type_Ary p_pEnd
, const char *const p_pchFormat )
{
for( ; p_pBegin != p_pEnd; ++p_pBegin )
printf( p_pchFormat, *p_pBegin );
}
先ほどの int 配列バージョンと比べると、ポインタを受け取る部分がテンプレート引数になっている部分だけが違いますね。 では使ってみましょう。今度は double の配列を渡します。
////////////////////////////////////////////////////////////////
// Alg_printf() の使用例。
void Use_Alg_printf()
{
double dAry[] = { 3.4, 5.2, 1.5 };
Alg_printf( dAry, dAry + 3, "%f, " );
}
// 結果
3.400000, 5.200000, 1.500000,
/////////////////////////////
このように int だけでなく double など、多くの組込型配列に使えるようになりました。これで、自作アルゴリズムの完成です。 実際に作ってみると、結構難しいかもしれません。初めは、元々あるアルゴリズムをちょっと作り直す、ということを繰り返し練習してみるといいでしょう。上の Alg_printf() なんて、 std::fill() とほとんど変わらないんですから。 |