|
(このコンテンツはメールマガジンの STL & iostream 入門に手を加えたものです。「 STL と iostream が使えるかのチェック」等はメールマガジンの方のページをご覧ください)
|
|
set と multiset ( #22 ) |
|
今回はコンテナクラスの std::set と std::multiset を紹介します。
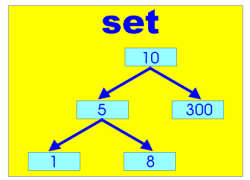 このふたつのクラスと、次次回紹介する std::map と std::multimap はこれまでのコンテナクラスとは値の格納方法が違います。この4つのクラスは「2分木」という方法で値を格納します。また、 std::set, std::multiset, std::map, std::multimap の4つのコンテナクラスを「連想コンテナ」と呼びます。
このふたつのクラスと、次次回紹介する std::map と std::multimap はこれまでのコンテナクラスとは値の格納方法が違います。この4つのクラスは「2分木」という方法で値を格納します。また、 std::set, std::multiset, std::map, std::multimap の4つのコンテナクラスを「連想コンテナ」と呼びます。std::vector などは「1列に並んだデータ」をイメージするものでした。 std::set などは「2分木」という規則に則ってデータを格納します。これは「ひとつの値がふたつの枝を持ち、右側の枝に大きい値、左側の枝に小さな値を継なげる形で大きな木を形成する」形式です。つまり「値を挿入する段階で、順序づけによるソートを行う」ということです。 まあとりあえず使ってみましょう。
////////////////////////////////////////////////////////////////
// std::set の使用例。
#pragma warning( disable : 4786 ) // VC での警告を取り除きます。
#include <stdio.h>
#include <set>
void Use_set()
{
std::set< int > cSet;
cSet.insert( 100 );
cSet.insert( 200 );
cSet.insert( 300 );
std::set< int >::iterator cIter
= cSet.find( 200 );
if( cIter != cSet.end() )
printf( "%d\n", *cIter );
}
// 結果
200
/////////////////////////////
std::set には push_back() などのメンバ関数がありません。2分木への挿入は必ず大小関係によって「どの枝に挿入するか」が決まるので、位置を指定できないからです。挿入は std::set::insert() を使って値を直接渡します。 std::set が最も役立つのは「検索」です。 std::set は挿入時にすでにソートされているので std::set::find() を使って検索すればアルゴリズムの std::find() よりもずっと速く検索できます。 もうひとつ例を見てみましょう。今度は std::set::lower_bound() と std::set::upper_bound() を使ってみます。
////////////////////////////////////////////////////////////////
// std::set::lower_bound() の使用例。
#pragma warning( disable : 4786 ) // VC での警告を取り除きます。
#include <stdio.h>
#include <set>
void Use_bound()
{
std::set< int > cSet;
cSet.insert( 500 );
cSet.insert( 200 );
cSet.insert( 300 );
cSet.insert( 100 );
cSet.insert( 400 );
std::set< int >::iterator cIBegin
= cSet.lower_bound( 150 ); // 下限を取得。
std::set< int >::iterator cIEnd
= cSet.upper_bound( 450 ); // 上限を取得。
for ( std::set< int >::iterator cIter = cIBegin
; cIter != cIEnd
; ++cIter )
printf( "%d, ", *cIter );
}
// 結果
200, 300, 400,
/////////////////////////////
std::set 内の各要素はソートされた形で格納されています。この中から「ある範囲」を返すメンバ関数が std::set::lower_bound() と std::set::upper_bound() です。このふたつのメンバ関数を呼び出すことで、上の例なら 150 から 450 の間の値を囲むようにイテレーターを取得することができます( std::set::upper_bound() は例によって「ひとつ先の要素」を指します)。 その前の「値の挿入」はバラバラにしていますが、各値は挿入時にはソートされています。なので、この「特定の値の範囲」の中をイテレーターで走査すれば、小さい順に並んだ各要素を順に取得することができます。 std::set のこの性質から、「高速な検索」や「データを順序立てて並べたい」場合に役立つことが分かると思います。 |
|
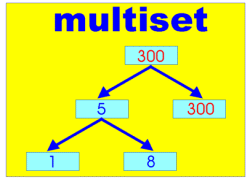 std::set とほとんど同じ機能を持つコンテナクラスに std::multiset があります。このふたつの違いは「 std::set は同じ要素を複数持てないが、 std::multiset は複数持てる」という点です。たとえば
std::set とほとんど同じ機能を持つコンテナクラスに std::multiset があります。このふたつの違いは「 std::set は同じ要素を複数持てないが、 std::multiset は複数持てる」という点です。たとえば
std::set< int > cSet;
cSet.insert( 100 );
cSet.insert( 100 );
としても 100 という要素は1個だけしか挿入されません。ですが
std::multiset< int > cMSet;
cMSet.insert( 100 );
cMSet.insert( 100 );
なら 100 という要素がふたつ挿入されます。これは今度紹介する std::map と std::multimap の場合には大きい意味を持つのですが、 std::set の場合には「値の重複」のメリットはあまりないと思います。 |
|
連想コンテナとプレディケート ( #23 ) |
|
std::set などの連想コンテナには、そのままだと使えないクラスがあります。例えば次の CInt のようなクラスとか。
////////////////////////////////////////////////////////////////
// CInt の間違った使用例。
#include <stdio.h>
#include <set>
class CInt
{
public:
int m_i;
CInt( int p_i )
: m_i( p_i )
{}
};
void Use_CInt_fail()
{
std::set< CInt > cSet;
cSet.insert( CInt( 100 ) ); // コンパイルエラー。
}
/////////////////////////////
連想コンテナは、ソートをするため要素の挿入時に「値の比較」を行います。値の比較は、デフォルトでは < 演算子で行うため、 CInt には < 演算子が必要ということになります。 演算子のオーバーロードができない場合には、 #09 で紹介したプレディケートを作成して、連想コンテナと一緒に使用します。
////////////////////////////////////////////////////////////////
// CPredForSet の使用例。
#include <stdio.h>
#include <set>
class CPredForSet
: public std::binary_function< CInt, CInt, bool >
{
public:
bool operator()( const CInt &p_rcIntL, const CInt &p_rcIntR ) const
{
return p_rcIntL.m_i < p_rcIntR.m_i;
}
};
// 使用例。
void Use_CPredForSet()
{
std::set< CInt, CPredForSet > cSet;
cSet.insert( CInt( 100 ) );
cSet.insert( CInt( 200 ) );
cSet.insert( CInt( 300 ) );
std::set< CInt, CPredForSet >::iterator cIter
= cSet.find( CInt( 200 ) );
if( cIter != cSet.end() )
printf( "%d\n", ( *cIter ).m_i );
}
// 結果
200
/////////////////////////////
std::set はテンプレート第2引数に「比較用プレディケート」を受け取ります。デフォルトは std::less というクラスで、このプレディケートはただ < で比較するというものです。そのため、 CInt のようなクラスでは比較できません。 代わりに CPredForSet というクラスを作ってプレディケートとして使用します。この中の operator()() は、ふたつの引数のメンバ変数を < 演算子で比較します。連想コンテナ用のプレディケートは、必ず < や > っぽい比較をする必要があります。 <= のように「値の一致」という結果を返さないプレディケートでないと、2分木がうまく作れないからです。 このプレディケートさえ作ってしまえば、 CInt も連想コンテナに使用できます。ちなみに > 演算子のものを作れば逆にソートできます。 STL でも std::greater() なんてものが用意されています。この辺はアルゴリズムの std::sort() などにも応用できる部分なので試してみてください。 連想コンテナに限らず、 STL のコンテナにクラスが使えるかどうかは「必要な演算子が用意されているかどうか」に掛かっています。関数オブジェクトでカバーできるのはこの「連想コンテナの比較」くらいなので、それほどコンテナに使用できるクラスは多くないかもしれません。 |
|
map と multimap ( #24 ) |
|
まず std::pair というクラス(正確には構造体)を紹介します。
////////////////////////////////////////////////////////////////
// std::pair の使用例。
#pragma warning( disable : 4786 ) // VC での警告を取り除きます。
#include <stdio.h>
#include <map>
void Use_pair()
{
std::pair< int, double > cPair( 2, 1.414 );
printf( "%d, %f\n", cPair.first, cPair.second );
}
// 結果
2, 1.414000
/////////////////////////////
 std::pair は「ふたつのデータを格納するクラス」です。各データは std::pair::first と std::pair::second のメンバ変数に入っています。標準 C++ ライブラリでは「ふたつの値をセットにして使う」ことが多いので、こういったクラスを用意してあるのです。
std::pair は「ふたつのデータを格納するクラス」です。各データは std::pair::first と std::pair::second のメンバ変数に入っています。標準 C++ ライブラリでは「ふたつの値をセットにして使う」ことが多いので、こういったクラスを用意してあるのです。さて本題に入りましょう。今回は std::map と std::multimap を紹介します。これらは前回の std::set 、 std::multiset と似た機能を持っています。唯一違うのは「ふたつの値をセットにして格納する」という点です。 例を見てみましょう。
////////////////////////////////////////////////////////////////
// std::map の使用例。
#pragma warning( disable : 4786 ) // VC での警告を取り除きます。
#include <stdio.h>
#include <map>
void Use_map()
{
typedef std::pair< int, double > type_id;
std::map< int, double > cMap;
cMap.insert( type_id( 2, 1.414 ) );
cMap.insert( type_id( 3, 1.732 ) );
cMap.insert( type_id( 5, 2.236 ) );
std::map< int, double >::iterator cIter
= cMap.find( 3 );
if( cIter != cMap.end() )
printf( "%d, %f\n", ( *cIter ).first, ( *cIter ).second );
}
// 結果
3, 1.732000
/////////////////////////////
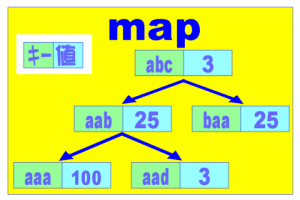 std::map はふたつの値をセットにして格納します。このとき、先ほどの std::pair を使います。
std::map はふたつの値をセットにして格納します。このとき、先ほどの std::pair を使います。std::pair のうち、 first を「キー」、 second を「値」といいます。 std::map も2分木を使ってソートしつつ挿入しますが、ソートの対象は「キー」のみです。「値」に関してはソートされません。 同じく std::map::find() を使った検索も、キーに対してのみ行われます。 std::map が「辞書」と呼ばれるのはこのためです、キーは英単語、値はその訳といったところになります。辞書の中ではキーによってソートされているわけです。 std::map のイテレーターが指す要素は std::pair 型なので、 first と second を使って値を取得する必要があります。 このように std::map::find() などは「キーに対して」のみ実行されます。「値に対して」行う場合には、端からひとつずつ調べていく必要があります。 std::multiset のように、 std::map の「キー重複版」 std::multimap も用意されています。 std::map は「キーの重複」が許されていません(逆に言うと「値の重複」はできます)。「キーの重複」をしたい場合には代わりに std::multimap を使用します。 このとき注意しなければならないのは「同じキーでも値は違う」という点です。人名辞典で「田中」の項がふたつあれば、それは当然別々の人でしょう。 std::multimap::find() を使用した場合には「田中 A 」しか取得できないので「田中 B 」は永遠に見つからない状態になってしまいます。 そこで使うのが std::multimap::equal_range() です。
////////////////////////////////////////////////////////////////
// std::equal_range の使用例。
#pragma warning( disable : 4786 ) // VC での警告を取り除きます。
#include <stdio.h>
#include <map>
void Use_equal_range()
{
typedef std::pair< int, int > type_ii;
typedef std::multimap< int, int >::iterator type_MMapIter;
std::multimap< int, int > cMMap;
cMMap.insert( type_ii( 100, 10 ) );
cMMap.insert( type_ii( 250, 50 ) );
cMMap.insert( type_ii( 100, -10 ) );
std::pair< type_MMapIter, type_MMapIter > cIterPair
= cMMap.equal_range( 100 );
for ( type_MMapIter cIter = cIterPair.first
; cIter != cIterPair.second
; ++cIter )
printf( "%d, ", ( *cIter ).second );
}
// 結果
10, -10,
/////////////////////////////
std::multimap::equal_range() は引数がキーになっている範囲をふたつのイテレーターとして返します。 std::multimap 内はキーでソートされているので、同じキーならかならず並んでいます。その並ぶ範囲を返します。 ふたつのイテレーターは std::pair にひとつずつ入っています。このように std::pair は std::map 専用というわけではないのです(ちなみに std::multiset::equal_range() も std::pair でふたつのイテレーターを返します)。このふたつのイテレーターの間を走査すれば、特定のキーが持つすべての値を取得することができます。 このように、 std::set std::map std::multiset std::multimap の4つの連想コンテナは、自分が持っているメンバ関数を多用します。そのため、アルゴリズムなどとちょっと連携が取りにくいかもしれません。でも、 equal_range() のようにたいがいのメンバ関数はイテレーターを返します。これをうまく使って、アルゴリズムに組み込むようにしましょう。 |
|
|
|