






最後は文字列についてです。
MFCにはとても便利なCStringクラスがありますが、それをどう使えばいいのか、やや遠回り気味に説明したいと思います。
ちなみに文字列やポインタについては、Codianの「ポインタ」でも解説していますのでそちらもどうぞ。
C/C++言語の文字列型
なんてものは存在しません!! Visual Basic他、多くの言語は簡単に文字列を操作できる「文字列型」を持っていますが、C/C++言語にはありません。
これは、C言語が「メモリ」に縛られているからです。というわけで、まず変数とメモリの関係について説明しましょう。
変数を宣言するということは、その変数のサイズ分だけメモリ領域を借りる、ということです。
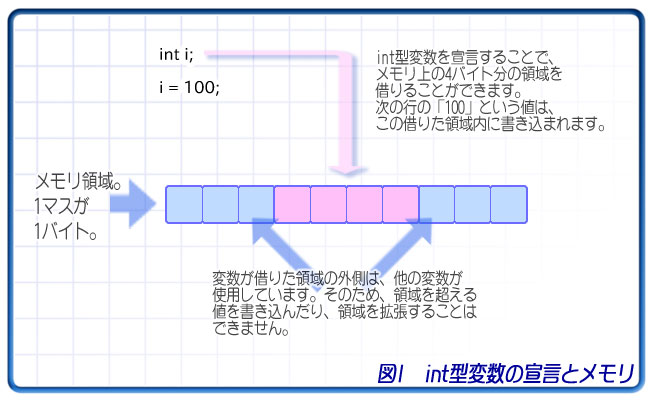
例えば、int型。Windows XPでは、int型の変数に32ビット=4バイト=-2,147,483,648~2,147,483,647までの値を入れることができます。これは、int型として宣言された変数にはメモリ上の4バイト分の領域が割り当てられ、その範囲内でのみ値を変えられるということです(参考:整数のなかみ(後編))。
変数は、宣言した型のサイズだけメモリを借り、その範囲内だけ使用することができます。借りた領域をむやみやたらに変えることはできません。その領域の隣は、他の変数が使っているかもしれませんから。
文字型
さて、ここで文字を扱う型について見てみましょう。C言語には、文字列型はありませんが文字型は存在します。それはchar型です。
char ch;
// この変数に「A」1文字を入れます。
ch = 'A';
// ch = 0x41; // 上の行と同じ。'A'は16進数の41です。
// 文字として出力します。
TRACE( "%c\n", ch );
// A
// 16進数として出力します。
TRACE( "%X\n", ch );
// 41
// 文字型の変数を宣言します。 char ch; // この変数に「A」1文字を入れます。 ch = 'A'; // ch = 0x41; // 上の行と同じ。'A'は16進数の41です。 // 文字として出力します。 TRACE( "%c\n", ch ); // A // 16進数として出力します。 TRACE( "%X\n", ch ); // 41
このプログラムでは、char型の変数chを宣言して、「A」の文字にあたる値(16進数の0x41)を格納しています。
char型はint同様、整数値を格納するための型です。ただし、int型よりも小さく、8ビットのサイズしかありません。
char型の変数は8ビット=1バイトのサイズなので、8ビット=1バイト=-128~127までの値が入ります。符号があると考えにくいので符号のないunsigned char型で考えると、変数1つに0~255の値が入ることになります。
この値が、文字を表します。大文字の「A」は10進数で65、16進数で0x41になります。プログラム中では、「'A'」がそのまま0x41という整数値になりますので、このプログラムではch変数に0x41という整数値が格納されることになるわけです。
どの文字がどの値かということは、MSDNのC++言語リファレンス「ASCII 文字コード」というページや、IMEに付いている文字パレットなどを見て確認してください。
文字型の配列
文字型はたった一文字だけしか扱えません。複数の文字、つまり文字列を扱うためには文字型の配列を宣言して、要素ひとつひとつに文字を入れるという方法を取ります。
char pchTest[32];
pchTest[0] = 'A'; // 「A」1文字を入れます。
pchTest[1] = 'B'; // 「B」1文字を入れます。
pchTest[2] = 'C'; // 「C」1文字を入れます。
pchTest[3] = '\0'; // 終端文字を入れます。
// 文字列として出力します。
TRACE( "%s\n", pchTest );
// ABC
// char型の配列を宣言します。要素数は32。 char pchTest[32]; pchTest[0] = 'A'; // 「A」1文字を入れます。 pchTest[1] = 'B'; // 「B」1文字を入れます。 pchTest[2] = 'C'; // 「C」1文字を入れます。 pchTest[3] = '\0'; // 終端文字を入れます。 // 文字列として出力します。 TRACE( "%s\n", pchTest ); // ABC
このプログラムは、char型の配列(要素数32)pchTest変数を宣言し、その0番目~2番目の要素に'A'~'C'を格納して、3番目の要素に終端文字を格納して出力しています。
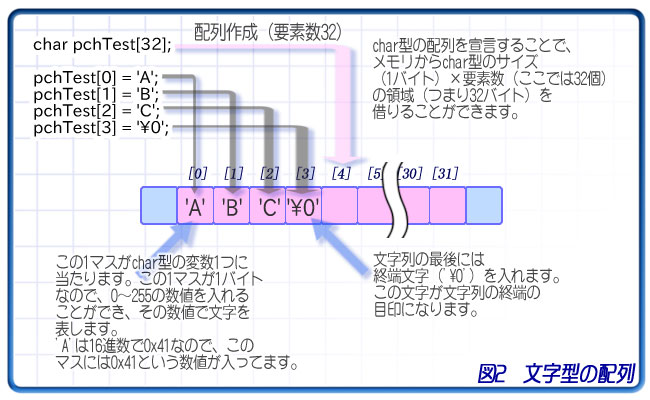
このように、文字列はchar型の配列として作り、ひとつひとつの要素に1文字ずつ入れられるという形になります。
文字列の最後には「どこが文字列の終わりか」を示す文字、終端文字(NULL文字)というものを最後に入れておきます。プログラムに文字として書く場合は'\0'(見た目は2文字ですが1文字として扱われます)と書きます。この文字に割り当てられている整数値は「0」です。MSDNなどでよく見る「NULL で終わる文字列」や「null-terminated string」は、この終端文字のことを指します。
また、文字型の配列は、次のように宣言することもできます。
// それぞれの要素に'A''B''C'\0'を格納します。
// 要素数は文字数分の4になります。
char pchTest[] = "ABC";
// 文字列として出力します。
TRACE( "%s\n", pchTest );
// ABC
// char型の配列を宣言して // それぞれの要素に'A''B''C'\0'を格納します。 // 要素数は文字数分の4になります。 char pchTest[] = "ABC"; // 文字列として出力します。 TRACE( "%s\n", pchTest ); // ABC
このプログラムは、char型の配列(要素数4)pchTest変数を宣言し、その0番目~2番目の要素に'A'~'C'を格納して、3番目の要素に終端文字を格納し、出力しています。
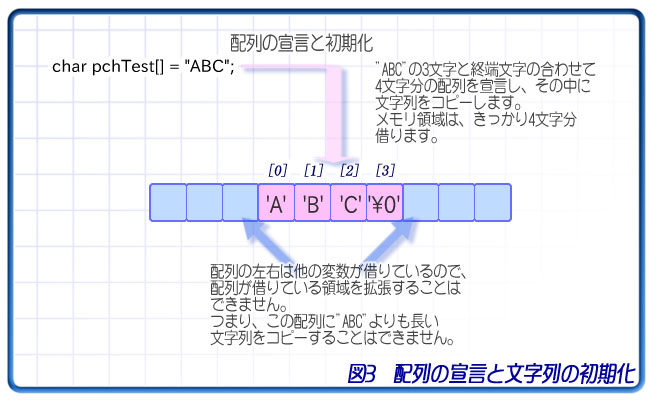
このように、配列の宣言と同時に「"文字列"」で初期化すると、その文字列が入る要素数の配列が宣言されます。この場合は、自動的にchar型×4の配列が作られることになります。
文字数より1多い理由は、最後に終端文字が入るからです。ダブルクォーテーションで囲った文字列(これを「文字列リテラル」と言います)は、最後に終端文字が入っていると見なされるので、「ABC」に加えて「\0」の4文字分だけ配列が作られ、この4文字が格納されます。
このように、文字列とは「文字型の配列」の各要素に「文字に当たる整数値」が格納されたものです。
文章などを扱う場合、その配列のサイズは2~無限大となるでしょう。ですが、その配列も、結局は「メモリの特定の範囲を借りただけ」です。そのため、たとえ文章が長くなって配列を長くしたくても、「借りた場所の隣」に他の変数があれば長くすることができません。
このような制約から、C言語には「文字列型」がないわけです。
C言語には後述するmalloc()/free()等の、メモリを好きなときに好きなサイズ借りる関数があり、メモリ操作に長けた言語と言えます。そのため、可変長の変数を言語の機能として持つよりも、プログラマーが自分で使用し管理することを望んだのだと思われます。
文字列操作系関数
サンプルプログラム2では、文字型配列の要素にひとつずつ文字を入れていました。このように、ある文字列を配列にコピーする場合には、1文字ずつコピーする必要があります。
一見、次のように「=」を使ってコピーできそうですが、これはできません。
char pchTest[32];
// その先頭要素のアドレスを出力します。
TRACE( "%X, %X\n", pchTest, &pchTest[0] );
// 12F624, 12F624
// 添え字のない配列は、先頭要素のポインタになります。
TRACE( "%X\n", "ABC" );
// 5B44C4
// ""で囲まれた文字列は、実際は文字列が置かれた先の
// ポインタになります。
// よって、これはできません。
// pchTest = "ABC";
// MxA09_VC6Dlg.cpp(226) : error C2440: '='
// : 'char [4]' から 'char [32]' に変換することはできません。
// この変換が可能なコンテキストはありません。
// ……というコンパイルエラーになります。
// char型の配列を宣言します。要素数は32。 char pchTest[32]; // その先頭要素のアドレスを出力します。 TRACE( "%X, %X\n", pchTest, &pchTest[0] ); // 12F624, 12F624 // 添え字のない配列は、先頭要素のポインタになります。 TRACE( "%X\n", "ABC" ); // 5B44C4 // ""で囲まれた文字列は、実際は文字列が置かれた先の // ポインタになります。 // よって、これはできません。 // pchTest = "ABC"; // MxA09_VC6Dlg.cpp(226) : error C2440: '=' // : 'char [4]' から 'char [32]' に変換することはできません。 // この変換が可能なコンテキストはありません。 // ……というコンパイルエラーになります。
配列として宣言された変数の「要素の位置」([0]とかのこと。「添え字」と言います)を省くと、配列の先頭要素を指すポインタという意味になります。
また"ABC"といった文字列はメモリ上にとりあえず置かれた文字列"ABC"の先頭の文字を指すポインタという意味になります。
つまり、「chTest = "ABC"」というプログラムは、本来は配列を指しているポインタに別のポインタが持つアドレスをコピーするということになります。もしこれができてしまうと、元の配列は使えなくなってしまうことになってしまいます。(まぁ、実際にはコンパイルエラーが発生するんで、ビルドできませんが)。

このように、文字列は=演算子で簡単にコピーすることができないので、1文字ずつコピーする必要があります。では文字列のコピーを簡単にするにはどうすればいいのかというと、ちゃんとそのための関数が用意されているのでそれを使用します。
char pchTest[32];
// 文字列をコピーします。
strcpy( pchTest, "ABC" );
// 配列の中身を出力します。
TRACE( "%s\n", pchTest );
// ABC
// char型の配列を宣言します。要素数は32。 char pchTest[32]; // 文字列をコピーします。 strcpy( pchTest, "ABC" ); // 配列の中身を出力します。 TRACE( "%s\n", pchTest ); // ABC
このサンプルプログラムは、char型の配列を用意して、そこにstrcpy()関数で文字列をコピーしています。
strcpy()は「ランタイムライブラリ」に含まれる関数のひとつです。この関数は第1引数に「コピー先の配列を指すポインタ」、第2引数に「コピー元の文字列」を渡すことで、サンプルプログラム2のような文字列のコピーを行います。
ランタイムライブラリは、C言語に付いている関数群です。付属しているものなので準備をしなくても使えますし、文字列の操作やデータの変換など、様々な機能を持つ関数がたくさん入っています。
ランタイムライブラリには文字列を結合する関数や、文字列の長さを取得する関数など、文字列に限っても様々な関数が存在します。例えば、前回(デバイスコンテキストとハンドル)の「文字列をデバイスコンテキストに描画する」部分でも、このランタイムライブラリの関数が使われています。
TextOut( hPaintDC, 0, 0, pchHello, strlen( pchHello ) );
strlen()関数は、文字列の長さを取得するための関数です。この例ではpchHello変数には"Hello, world!"が入っているので、strlen( pchHello )は「13」が返されます(この時は終端文字は含まれません)。
このstrlen()関数も、ランタイムライブラリに含まれています。このように、使いにくそうなC言語形式の文字列を様々な関数がサポートしていますので、ランタイムライブラリの関数は一通り見ておいた方がいいでしょう(参考:MSDN ランタイムライブラリリファレンス カテゴリ別ランタイム ルーチン)。
文字列へのポインタ
ここでstrcpy()関数の引数を詳しく見てみましょう。
MSDNのstrcpy()関数のリファレンスに、strcpy()関数の関数宣言が書かれています。
char *strDestination,
const char *strSource
);
char *strcpy( char *strDestination, const char *strSource );
第1引数はchar *型、第2引数はconst char *型となっています。つまり、両方ともポインタです。
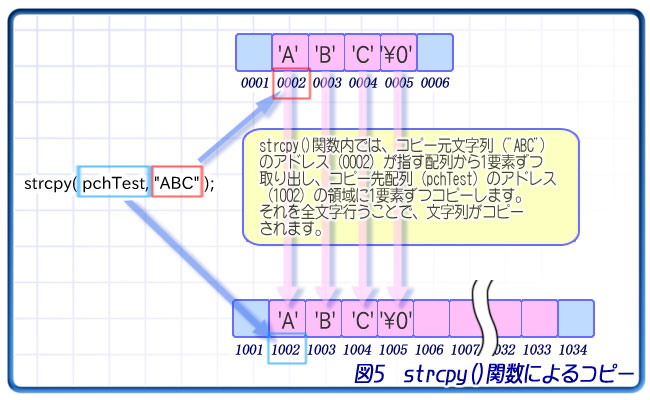
配列は、要素すべてを一度にコピーすることはできません。つまり、関数に文字列を渡す場合、その配列まるごとコピーして渡すことはできないということです(それができたらstrcpy()関数の意味がないですし)。
そこで、関数にはポインタを渡します。関数側は、ポインタだけを受け取って、それを元にメモリを見に行き、各文字を取得します。
また、コピー先の配列もそのポインタを受け取り、そのポインタを通して文字を配列の各要素にコピーします。文字列を受け取るための配列をあらかじめ作製しておき、その先頭へのポインタを関数に渡します。関数はそのポインタを使って配列の所在を知り、文字列を書き込んでいくわけです。
これら、文字列へのポインタはchar *型になります。前述したように、文字列はchar型の配列に入っています。その先頭要素へのポインタなので、charのポインタ、char *型になるわけです。strcpy()関数の引数はどちらもこのchar型のポインタですので、ここに文字列へのポインタと配列のポインタを渡せばいいわけです。
constの有無
ここで、strcpy()関数の第1引数と第2引数の違いに注目しましょう。第2引数にはconstが付いていますが、第1引数には付いていません。
引数にconstが付いている場合、関数はポインタが指し示す変数の中身を変更することができなくなります。これはつまり、第2引数に渡した文字列は、関数の中で中身が変えられることはない、つまり読み取り専用になる、ということです。
また、これを逆に考えれば、constの付いていない第1引数へと渡した文字列は変更されるということ、つまり書き込み専用ということを表しています。
strcpy()関数は、「第2引数の文字列を第1引数へとコピーする」という仕様になっていますが、実はこのconstの有無からそれを読み取ることができます。constが付いている第2引数にはコピーできないのですから、必然的にコピー先は第1引数になるわけです。
ちなみに、このconstは、自分で関数を作る場合にも役立ちます。
たとえば大きな構造体やクラスを引数に取る関数を作る場合。この場合、通常ポインタを使用します。これは、これらの引数をポインタにしない場合、引数で渡したときに全メンバがコピーされることになりますが、ポインタにすればアドレスのコピーだけで済むからです。
ですが、不用意にポインタを使用すると、本来は読み出して欲しいデータを誤って書き換えてしまう可能性が出てきます。関数内で渡されたポインタを通して各メンバに書き込んでしまうと、関数から戻った時には引数の中身が変わっていたということになってしまいます。
それを防ぐのがconstです。constポインタにすれば、ポインタが指し示すデータを書き換えられないよう、コンパイラがチェックしてくれます。そうすれば、その引数は自動的に読み出し専用になるというわけです。
もし自分で作った関数の引数をポインタにする場合は、このようなことも考慮してみるといいでしょう。「コンパイラにできることはコンパイラにさせる」、バグを減らすコツのひとつです。
LPTSTRとLPCTSTR
ここまではstrcpy()等、ランタイムライブラリについて説明してきました。
ここからはAPIについての説明になります。
APIには、ランタイムライブラリと同じように文字列を操作する関数があります。また、前述したTextOut()関数も文字列を受け取るAPIです。
ところが、APIの関数宣言を見ると、引数がchar *型ではありません。LPTSTRやLPCTSTRなんていうわけの分からない型になっています。
実際に、ランタイムライブラリとAPIを比較をしてみましょう。APIにはstrcpy()関数のAPI版であるlstrcpy()関数が存在します(参考:MSDN Win32 API lstrcpy() リファレンス)。使用方法はstrcpy()関数とまったく同じです。
char pchTest[32];
// 文字列をコピーします。
lstrcpy( pchTest, "ABC" );
// 配列の方を出力します。
TRACE( "%s\n", pchTest );
// ABC
// strcpy()とlstrcpy()の宣言を比較します。
// char * strcpy ( char * strDestination, const char *strSource );
// LPTSTR lstrcpy( LPTSTR lpString1 , LPCTSTR lpString2 );
// char型の配列を宣言します。要素数は32。 char pchTest[32]; // 文字列をコピーします。 lstrcpy( pchTest, "ABC" ); // 配列の方を出力します。 TRACE( "%s\n", pchTest ); // ABC // strcpy()とlstrcpy()の宣言を比較します。 // char * strcpy ( char * strDestination, const char *strSource ); // LPTSTR lstrcpy( LPTSTR lpString1 , LPCTSTR lpString2 );
この2つの関数、strcpy()関数とlstrcpy()関数を比較すると、引数が異なっています。lstrcpy()関数は、第1引数がLPTSTR型、第2引数がLPCTSTR型になっています。この2つの型が、char *型とconst char *型に代わるものなのです。
といっても実際にはほとんど違いはありません。APIのヘッダーファイル(Visual C++ 6.0をインストールしたフォルダの、VC98\Includeフォルダ内にあります)のWINNT.Hに、LPTSTR型とLPCTSTR型が定義されています。
(略)
typedef CHAR *LPSTR, *PSTR;
typedef CONST CHAR *LPCSTR, *PCSTR;
(略)
typedef LPSTR PTSTR, LPTSTR;
typedef LPCSTR LPCTSTR;
typedef char CHAR; (略) typedef CHAR *LPSTR, *PSTR; typedef CONST CHAR *LPCSTR, *PCSTR; (略) typedef LPSTR PTSTR, LPTSTR; typedef LPCSTR LPCTSTR;
typedefは、新しく型を定義するためのキーワードです。「typedef A B;」とすると、Bという名前でAという型が使えます。たとえば「typedef int *PInt;」とすれば、「PInt pi;」とすることでint *型のpi変数を宣言することができます。
CONSTは前述したconstと全く同じものです。constの有無によって、LPCTSTR型が読み取り専用、LPTSTR型が書き込み専用になります。
……ということは、この宣言は、以下のように置き換えられるということです。
(略)
typedef char *LPSTR, *PSTR;
typedef const char *LPCSTR, *PCSTR;
(略)
typedef char *PTSTR, LPTSTR;
typedef const char *LPCTSTR;
typedef char CHAR; (略) typedef char *LPSTR, *PSTR; typedef const char *LPCSTR, *PCSTR; (略) typedef char *PTSTR, LPTSTR; typedef const char *LPCTSTR;
というわけで、一見ランタイムライブラリとAPIとで型が違うように見えますが、実は同じchar型のポインタなのです。ですから、LPTSTRはchar *、LPCTSTRはconst char *に読み替えるようにしましょう。
ところが実は、場合によってはLPTSTR型やLPCTSTR型はchar型の文字列ではない場合があります。そもそも、単にchar型の文字列であればこんな置き換え必要ないわけです。わざわざLPTSTR型やLPCTSTR型という型を定義してAPIで使用しているということは、ちゃんと理由があるわけです。
その説明のために、まずプログラミングにおける「日本語」の扱いについて見ておきましょう。
「日本語」の扱い
これまで、文字列にはchar型の配列を使用してきました。
ですが、char型は1バイトのサイズなので、16進数で0x00~0xFFの範囲の数値、つまり256通りの数値しか格納できません。つまり256文字しか表現することができない、ということです。これでは日本語に含まれる「漢字」を表現するには足りません。
そこで考え出されたのが、char型ふたつで一組にするという方法です。2バイトあれば、65536種類もの文字を扱うことができますから、漢字も表現できます。
この「char型2つで1文字」とした文字を「ダブルバイト文字」と呼び、この文字のセットを「ダブルバイト文字セット(DBCS/Double-Byte Character Sets)」と呼びます。
ダブルバイト文字はWindowsで日本語の文字列を扱うときの一般的な方法です。
たとえば「あ」という文字は、16進数の0x82と0xA0という2つの数字で表し、char型の変数2つを使用して表現します。配列で言えば、要素2つを使用して、片方には0x82、もう片方には0xA0を格納し、この2要素で1文字とします。
プログラムで扱う場合、""で囲まれた文字列の中に日本語の文字列を書き込むと自動的にダブルバイト文字として扱われます。
// コピーします。
char pchDBCS[] = "あいABCう";
// これはもちろん出力できます。
TRACE( "%s\n", pchDBCS );
// あいABCう
// 1要素ずつ出力します。
// 終端文字も出力したいので「文字列の長さ+1」出力します。
int iLength = strlen( pchDBCS ) + 1;
for( int i = 0; i < iLength; ++i )
{
char ch = pchDBCS[i];
TRACE( "%X\n", ch );
}
// FFFFFF82
// FFFFFFA0
// FFFFFF82
// FFFFFFA2
// 41
// 42
// 43
// FFFFFF82
// FFFFFFA4
// 0
// (「FFFFFF」は、char型の値をint型とみなして
// 出力して付加されたものなので無視してください)
// 配列を宣言して、日本語の入った文字列を
// コピーします。
char pchDBCS[] = "あいABCう";
// これはもちろん出力できます。
TRACE( "%s\n", pchDBCS );
// あいABCう
// 1要素ずつ出力します。
// 終端文字も出力したいので「文字列の長さ+1」出力します。
int iLength = strlen( pchDBCS ) + 1;
for( int i = 0; i < iLength; ++i )
{
char ch = pchDBCS[i];
TRACE( "%X\n", ch );
}
// FFFFFF82
// FFFFFFA0
// FFFFFF82
// FFFFFFA2
// 41
// 42
// 43
// FFFFFF82
// FFFFFFA4
// 0
// (「FFFFFF」は、char型の値をint型とみなして
// 出力して付加されたものなので無視してください)
このプログラムのように、"あいABCう"という形で文字列中に日本語を使用すれば、自動的にダブルバイト文字の形式として配列に日本語が格納されます。日本語は1文字で配列の2要素を使用します。この例では、pchDBCS[0]には0x82が、pchDBCS[1]には0xA0が格納され、この2つの要素で「あ」を格納しているわけです。
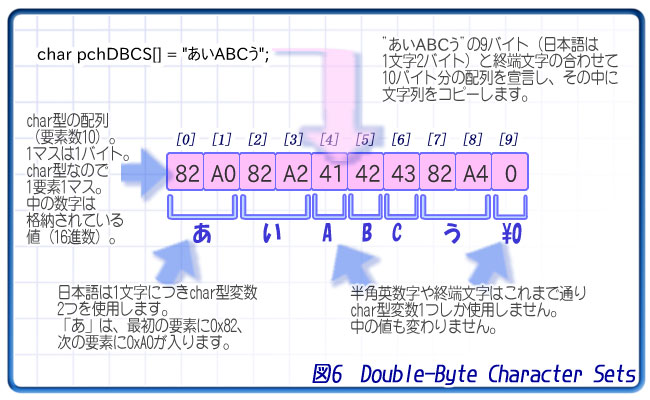
どの文字がどの値なのか、ということはMSDNには記載されていませんので、IMEの文字パレットをご覧ください。また、インターネットで調べる際には、Windowsで使用されるMBCSは「MS932」「Shift-JIS」と呼ばれていますのでこちらで調べてみてください。
さらに、もっと文字数が多いときのためにchar型を何個も組み合わせてひとつの文字を表現するという「マルチバイト文字セット(MBCS/Multibyte Character Sets)」というものもあります。ダブルバイト文字(DBCS)はMBCSの一種です。MSDN内ではDBCSではなくMBCSで説明が書かれていますから、MBCSと書かれていたらそれはこのダブルバイト文字のことだと読み替えてください。
このように、文字列の中で日本語を使用する場合、通常はこのダブルバイト文字を使用しています。
Windowsでは、これとは別に、もうひとつ日本語を扱う方法があります。
それはUnicode(ユニコード)です。これは、文字を格納する変数にchar型を使用しません。代わりにwchar_t型を使用します。
wchar_t型はchar型と同じく文字を格納するための型です。char型と異なるのは、サイズが2バイトという点です。つまりchar型の倍のサイズ、2文字分のサイズということです。また、このように倍のサイズなので、wchar_t型の文字を「Wide-character」とも呼びます。
Unicodeの場合、たとえば「あ」という文字は、16進数の0x3042という数字で表します。この数値を、wchar_t型配列の1要素に格納します。0x3042は2バイトの値ですが、wchar_t型も2バイトなので格納できるというわけです。
ダブルバイト文字と異なり、同じ「あ」という文字でも数値が異なるという点に注意してください。ダブルバイト文字の「あ」は0x82と0xA0のペアですが、Unicodeの「あ」は0x3042になります。
英数字の場合、値そのものはダブルバイト文字もUnicodeも同じです。ただ、変数の使い方が違います。
ダブルバイト文字と違い、英数字を格納する場合でもwchar_t型の変数を使用します。ダブルバイト文字の場合「A」という文字は0x41でchar型の変数1つに格納しますが、Unicodeの場合「A」という文字は0x0041、つまり2バイトになり、wchar_t型の変数1つに格納します。終端文字も、値は同じ0ですがこれも2バイトになります。
プログラムで扱う場合、L""で囲まれた文字列の中に日本語の文字列を書き込むと自動的にUnicodeとして扱われます。つまり、文字列の前に「L」を付ければその文字列はUnicodeになるということです。
setlocale( LC_ALL, "japanese" );
// Unicodeを使用するときは、文字列の前に「L」を付けます。
wchar_t pwchUnicode[] = L"あいABCう";
// TRACEマクロで出力するときは「%s」を「%S」にします。
TRACE( "%S\n", pwchUnicode );
// 1要素ずつ出力します。
// 終端文字も出力したいので「文字列の長さ+1」出力します。
// wcslen()関数は、strlen()関数のUnicode版です。
int iLength = wcslen( pwchUnicode ) + 1;
for( int i = 0; i < iLength; ++i )
{
wchar_t wch = pwchUnicode[i];
TRACE( "%X\n", wch );
}
// 3042
// 3044
// 41
// 42
// 43
// 3046
// 0
// UnicodeをTRACEマクロで出力するため、ロケールをセットします。
setlocale( LC_ALL, "japanese" );
// Unicodeを使用するときは、文字列の前に「L」を付けます。
wchar_t pwchUnicode[] = L"あいABCう";
// TRACEマクロで出力するときは「%s」を「%S」にします。
TRACE( "%S\n", pwchUnicode );
// 1要素ずつ出力します。
// 終端文字も出力したいので「文字列の長さ+1」出力します。
// wcslen()関数は、strlen()関数のUnicode版です。
int iLength = wcslen( pwchUnicode ) + 1;
for( int i = 0; i < iLength; ++i )
{
wchar_t wch = pwchUnicode[i];
TRACE( "%X\n", wch );
}
// 3042
// 3044
// 41
// 42
// 43
// 3046
// 0
このプログラムのように、L"あいABCう"という形で文字列中に日本語を使用すれば、自動的にUnicodeの形式として日本語が配列に格納されます。ただし、その配列はwchar_t型にする必要があります。日本語も英数字も、1要素に1文字格納されるので、この例ではpwchUnicode[0]には「あ」の0x3042が格納されています。
また、Unicodeを使用する場合には、Unicode用の関数や引数を使用する必要があります。文字列の長さ(バイト単位のサイズではなく、文字数です)を取得する関数はstrlen()関数ではなくwcslen()関数になります。また、TRACEマクロやprintf()関数で出力する場合には"%s"ではなく"%S"(「s」が大文字)を使用します。ちなみにこれらはランタイムライブラリに標準で備わっているものです。
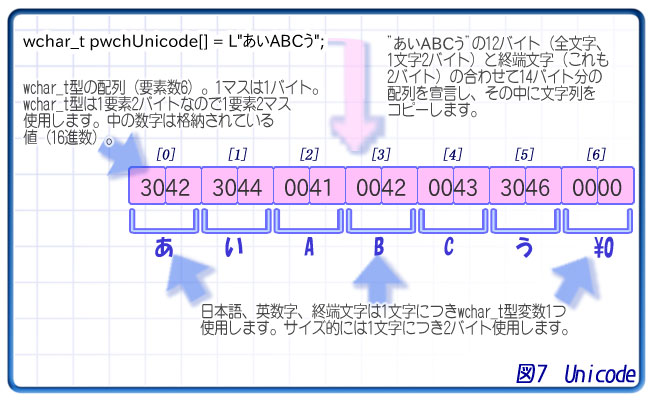
どの文字がどの値なのか、ということはMSDNには記載されていません。IMEの文字パレット等をご覧ください。また、インターネットで調べる際には「Unicode」もしくは「UTF-16」で検索してください(広義のUnicodeはUTF-16以外のものも含んでいるためご注意ください)。
このUnicodeにはダブルバイト文字にない大きな特徴があります。
それは日本語以外のあらゆる文字を表現できるという点です。
ダブルバイト文字は日本語しか扱えませんが、Unicodeであれば日本語だけでなく中国語(繁体字や簡体字)やアラビア語等も扱うことができます。インターネットの文書には様々な言語が使用されているため、それらを同じように扱うことができるUnicodeがWindowsでもサポートされているわけです。
このように、単純にメリットだけを考えればダブルバイト文字よりもUnicodeの方がいいように感じられます。
ところが、Windowsではダブルバイト文字の方が一般的です。これは、Windows95ではUnicodeを使うことができず、その後のWindows 98やWindows Meでも完全には使用できなかったため、長い間ダブルバイト文字が使われてきたからです。また、インターネットが普及するまでは実質Unicodeが必要なかったという面もあります。
UnicodeはWindows NT系では使用できるため、Windows 2000やWindows XPでは使用できます。そして、Windows VistaではむしろUnicodeの方がメインになっています。つまり、「昔のプログラムはダブルバイト文字だけど、将来的にはUnicodeに移行する必要がある」というわけです。
そこで取られた方法が、「コンパイル時の設定によって切り替えられるようにしよう」というものです。
「ダブルバイト文字」「Unicode」のどちらも使用できるようにプログラムを書くと、、設定を変更するだけで切り替えられるようにする、という方法が用意されています。この方法を使用することで、「ダブルバイト文字」「Unicode」どちらにもプログラムを対応させることができるわけです。
この切り替え機能を使用したのが、以下のプログラムです。
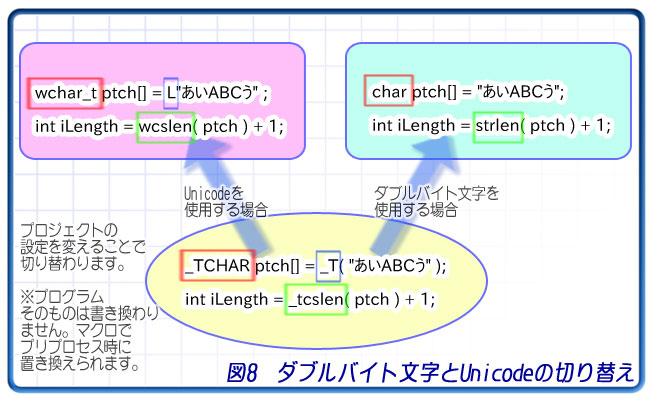
// _TCHAR型はDBCSではchar型、Unicodeではwchar_t型になります。
// _Tは、Unicodeの時に文字列の前に「L」を付けます。
_TCHAR ptch[] = _T( "あいABCう" );
// TRACEマクロで出力します。
// 「%s」を指定すればDBCSでもUnicodeでも出力できます。
TRACE( _T( "%s\n" ), ptch );
// あいABCう
// 1要素ずつ出力します。
// 終端文字も出力したいので「文字列の長さ+1」出力します。
// _tcslen()関数はDBCSの時はstrlen()関数、
// Unicodeの時はwcslen()関数になります。
int iLength = _tcslen( ptch ) + 1;
for( int i = 0; i < iLength; ++i )
{
_TCHAR tch = ptch[i];
TRACE1( "%X\n", tch );
}
// 出力結果は、DBCSを使用したときにはプログラム11、
// Unicodeを使用したときにはプログラム12と同じになります。
// 文字型は_TCHAR型を使用し、文字列は_T()で囲みます。
// _TCHAR型はDBCSではchar型、Unicodeではwchar_t型になります。
// _Tは、Unicodeの時に文字列の前に「L」を付けます。
_TCHAR ptch[] = _T( "あいABCう" );
// TRACEマクロで出力します。
// 「%s」を指定すればDBCSでもUnicodeでも出力できます。
TRACE( _T( "%s\n" ), ptch );
// あいABCう
// 1要素ずつ出力します。
// 終端文字も出力したいので「文字列の長さ+1」出力します。
// _tcslen()関数はDBCSの時はstrlen()関数、
// Unicodeの時はwcslen()関数になります。
int iLength = _tcslen( ptch ) + 1;
for( int i = 0; i < iLength; ++i )
{
_TCHAR tch = ptch[i];
TRACE1( "%X\n", tch );
}
// 出力結果は、DBCSを使用したときにはプログラム11、
// Unicodeを使用したときにはプログラム12と同じになります。
このサンプルプログラムの構造は、サンプルプログラム11およびサンプルプログラム12と全く同じです。そして、このプログラムはそのどちらのプログラムにも切り替えることができます。つまりこのプログラムはダブルバイト文字とUnicodeの両方に対応しているということです。
このプログラムの_TCHAR、_T、_tcslen()関数は設定をダブルバイト文字にするかUnicodeにするか、設定を変更することで以下のように切り替わります。
| ダブルバイト文字 | Unicode | |
|---|---|---|
| _TCHAR | char | wchar_t |
| _T | 文字列そのまま | 文字列の前に「L」 |
| _tcslen()関数 | strlen()関数 | wcslen()関数 |
この切り替え機能が組み込まれた変数型や関数には、プレフィックスとして「_T」「_t」「T」が付けられています。これらが付いたものを使用することで、ダブルバイト文字もUnicodeも対応できるというわけです。
(設定の切り替え方法についてはここでは説明しません。詳しくはサンプルプロジェクトをご覧ください)
ここでLPTSTR型とLPCTSTR型に話を戻しましょう。
実は、このLPTSTR型とLPCTSTR型も、ダブルバイト文字とUnicodeの切り替え機能が備わった型なのです。
前述したように、通常LPTSTR型はchar *型、LPCTSTR型はconst char *型になります。
ところがUnicodeを使用する設定だと、LPTSTR型はwchar_t *型、LPCTSTR型はconst wchar_t *型になります。
つまり、LPTSTR/LPCTSTRはchar */const char *かwchar_t */const wchar_t *かのどちらかに切り替えることができるわけです。
逆に言うと、切り替え機能の一環として「文字列のポインタ」を扱うため、LPTSTR型とLPCTSTR型が用意されているということです。
……とはいえ、Unicodeを使用しない場合には、LPTSTR型もLPCTSTR型も、単なる「char型のポインタ」に過ぎません。ですから、LPTSTR型やLPCTSTR型が出てきても「あ、これはchar型のポインタだ」と考えればいいでしょう。
ちなみにLPCTSTRのうち、LPCT「STR」は文字列を表す「String」、LPC「T」STRは今説明した「切り替え機能」を示す「T」、LP「C」TSTRは「const」を意味します。
では「LP」はなにかというと、これは「Long Pointer」の略です。Windows 3.1のような昔のWindowsは、ポインタが16ビットサイズでした。それに対して、Windows95以降はポインタが32ビットサイズになり、これまでと区別してlong型(long型は32ビット)のポインタ(Long Pointer)の略である「LP」が付けられ、それが今も残っているというわけです。
さて、この切り替え機能、実は文字列を扱うAPIのほとんどに備わっています。
まず、「すべてはWinMain()から」で、MFCではWinMain()関数ではなく_tWinMain()関数を使っていたことを思いだしてください。この_tWinMain()関数は、WinMain()関数に切り替え機能が付いたものですので、_tWinMain()関数を使用すればダブルバイト文字にもUnicodeにも対応できるというわけです。
またAPIだけでなくランタイムライブラリも切り替え機能が備わっています。サンプルプログラム13で説明したように、strlen()関数の切り替え機能版として_tcslen()関数が用意されています。この_tcslen()関数を使用すればダブルバイト文字にもUnicodeにも対応できるというわけです。
このように、APIやランタイムにはダブルバイト文字とUnicodeの切り替え機能が備わっています。
WindowsはUnicodeを使用する方向に向かっているため、将来の移植性を考えるのであればこの切り替え機能を使用した方がいいでしょう。切り替え機能を使用してもUnicode版に切り替えなければ使用しないのと同じという点もメリットです。
ただ、Windows XPまでであればUnicodeを使用する必要が特にないことや、プログラムの量が増えたり、可読性が落ちたり、切り替え機能を使用していない一般的なサンプルプログラムをそのまま移植できなかったりと、プログラミングに掛かる負担が増えることを考えると使用しないという選択肢もあります。
いずれにせよ、どちらかに統一した方がいいでしょう。混在させるとバグの元となりかねません。
CString
MFCにはとても便利な、文字列を扱うためのクラスがあります。
それは皆様おなじみのCStringクラスです。
MFCを使用しているのであれば、恐らく文字列操作はCStringクラスで行っていることでしょう。事実、CStringクラスは文字列操作におけるほとんどの機能を持っています。+演算子などを用いた分かりやすい文字列操作、大文字小文字の変換や文字列の検索等が可能で、何より文字列配列と異なりサイズを増やして文字列を追加することができます。
CString cString = "あいうえお";
// 出力します。
TRACE( "%s\n", cString );
// あいうえお
// 別の文字列で上書きします。
// char型配列と違って、=演算子で上書きできます。
cString = "かき";
TRACE( "%s\n", cString );
// かき
// 文字列を追加します。
// char型配列と違って、+演算子で追加できます。
cString += "くけこ";
TRACE( "%s\n", cString );
// かきくけこ
// CString::Compare()メンバ関数で比較します。
if( cString.Compare( "かきくけこ" ) == 0 )
{
TRACE( "文字列は「かきくけこ」です。\n" );
}
// 文字列は「かきくけこ」です。
// CStringクラスの変数を宣言して文字列を格納します。
CString cString = "あいうえお";
// 出力します。
TRACE( "%s\n", cString );
// あいうえお
// 別の文字列で上書きします。
// char型配列と違って、=演算子で上書きできます。
cString = "かき";
TRACE( "%s\n", cString );
// かき
// 文字列を追加します。
// char型配列と違って、+演算子で追加できます。
cString += "くけこ";
TRACE( "%s\n", cString );
// かきくけこ
// CString::Compare()メンバ関数で比較します。
if( cString.Compare( "かきくけこ" ) == 0 )
{
TRACE( "文字列は「かきくけこ」です。\n" );
}
// 文字列は「かきくけこ」です。
このプログラムのように、CStringクラスはchar型配列と異なり、演算子を使用した直感的な操作で文字列を扱うことができます。また、Compare()メンバ関数のような便利なメンバ関数も備えています。
このようにMFCの便利なクラスであるCStringクラス。
このクラスの中では一見何か特殊なことをしているように見えますが、そんなことはないんです。実は、CStringもランタイムライブラリを使っているんです。
例えば、サンプルプログラム14で使用している、文字列を比較するCStringクラスのCompare()メンバ関数。このメンバ関数では、内部で_tcscmp()というランタイムライブラリの関数を使用しています。
// 切り替え機能を持った関数なので、文字列も
// 対応させておきます。
_TCHAR ptch[] = _T( "かきくけこ" );
// _tcscmp()関数で比較します。
if( _tcscmp( ptch,_T( "かきくけこ" ) ) == 0 )
{
TRACE( "文字列は「かきくけこ」です。\n" );
}
// 文字列は「かきくけこ」です。
// _tcscmp()関数は、ダブルバイト文字とUnicodeの
// 切り替え機能を持った関数なので、文字列も
// 対応させておきます。
_TCHAR ptch[] = _T( "かきくけこ" );
// _tcscmp()関数で比較します。
if( _tcscmp( ptch,_T( "かきくけこ" ) ) == 0 )
{
TRACE( "文字列は「かきくけこ」です。\n" );
}
// 文字列は「かきくけこ」です。
CStringクラスのCompare()メンバ関数は、内部でランタイムライブラリの_tcscmp()関数を呼び出します。つまり、「比較」という処理をMFC独自に実装しているわけではなく、_tcscmp()関数の機能を借りているというわけです。
また、_tが付いていることから分かる通り、ダブルバイト文字とUnicodeの切り替え機能も持っています。ちなみにこの関数は、ランタイムライブラリのstrcmp()関数の「切り替え機能版」ですので、使用例を調べる場合は「strcmp()」で調べた方が情報が多いでしょう。
CStringクラスの特徴のひとつに「サイズを気にせず文字列を追加できる」という点があります。
サンプルプログラム3や図3で説明したように、文字列を入れる領域を配列として用意すると、その配列より大きい文字列を入れようとしても、配列の要素数を拡張できないため入れることができません。配列のとなりは他の変数が利用しているかもしれないので、勝手に拡張することができないからです。
また、配列は実行時に好きなサイズの領域を借りることができません。配列としてメモリ領域を借りる場合、必ず「プログラムの中でサイズを決める」必要があります。サンプルプログラム2では要素数32と指定していますし、サンプルプログラム3も文字数+終端文字の4が指定されていることになります。つまり、配列の場合は初めから借りるサイズが決められている、というわけです。配列の要素数を決める部分に変数を使用してもコンパイルエラーになってしまいます。
// (実際には画面から入力したりコマンドライン引数として
// 渡された文字列になります)
char pchFrom[] = "ABC";
// この文字列がきっちり入る領域を作成してみます。
// そのためにサイズを取得します。
// 終端文字も含めるので「文字列の長さ+1」にします。
int iLength = strlen( pchFrom ) + 1;
// この文字列が入るサイズの配列を宣言する……
// ……ことはできません。
// char pchTo[iLength];
// error C2057: 定数式が必要です。
// このようにコンパイルエラーが発生します。
// あらかじめ、コピー元の文字列を用意しておきます。 // (実際には画面から入力したりコマンドライン引数として // 渡された文字列になります) char pchFrom[] = "ABC"; // この文字列がきっちり入る領域を作成してみます。 // そのためにサイズを取得します。 // 終端文字も含めるので「文字列の長さ+1」にします。 int iLength = strlen( pchFrom ) + 1; // この文字列が入るサイズの配列を宣言する…… // ……ことはできません。 // char pchTo[iLength]; // error C2057: 定数式が必要です。 // このようにコンパイルエラーが発生します。
このように「char pchTo[この部分];」に変数を入れることはできません。配列のサイズはプログラムの作成段階で決められ、実行中に好きなサイズを指定することはできないからです。
ではCStringクラスはどのようにこの問題を解決しているかというと、それは「実行時にサイズを指定してメモリ領域を借りる」という方法を取っているからです。
実は配列とは別の方法で、プログラムの実行中に好きなサイズの領域を借りる方法が用意されているのです。この方法を使えば、文字列が長くなってもその長さ分の領域を借りればいいので問題ありません。
この、任意のサイズの領域を借りる方法の1つは、malloc()というランタイムライブラリの関数を使用するというものです。
// (実際には画面から入力したりコマンドライン引数として
// 渡された文字列になります)
char pchFrom[] = "ABC";
// この文字列がきっちり入る領域を、動的に作成します。
// そのためにサイズを取得します。
// 終端文字も含めるので「文字列の長さ+1」にします。
int iLength = strlen( pchFrom ) + 1;
// char型のポインタを用意しておきます。
char *pchTo;
// コピー元の文字列の長さの分だけメモリ領域を借り、
// その先頭アドレスを受け取ってポインタに格納します。
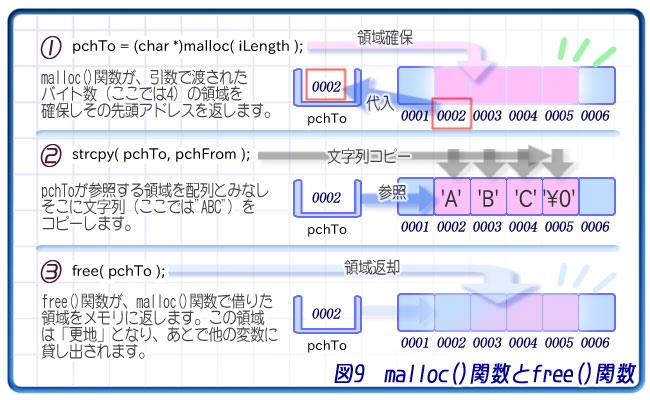
pchTo = (char *)malloc( iLength );
// そこに文字列をコピーします。
strcpy( pchTo, pchFrom );
// そして出力します。
TRACE( "%s\n", pchTo );
// ABC
// 借りた領域を返します。
free( pchTo );
// あらかじめ、コピー元の文字列を用意しておきます。 // (実際には画面から入力したりコマンドライン引数として // 渡された文字列になります) char pchFrom[] = "ABC"; // この文字列がきっちり入る領域を、動的に作成します。 // そのためにサイズを取得します。 // 終端文字も含めるので「文字列の長さ+1」にします。 int iLength = strlen( pchFrom ) + 1; // char型のポインタを用意しておきます。 char *pchTo; // コピー元の文字列の長さの分だけメモリ領域を借り、 // その先頭アドレスを受け取ってポインタに格納します。 pchTo = (char *)malloc( iLength ); // そこに文字列をコピーします。 strcpy( pchTo, pchFrom ); // そして出力します。 TRACE( "%s\n", pchTo ); // ABC // 借りた領域を返します。 free( pchTo );
このサンプルプログラムでは、まずmalloc()関数で、コピー元の文字列がすっぽり入る領域を取得します。
malloc()関数はランタイムライブラリの関数の1つです。この関数は、引数で指定したバイト数だけメモリから領域を借り、その先頭アドレスを戻り値として返します。配列と異なり、実行時に好きなサイズを借りることができるわけです。
返されたアドレスをポインタとして受け取ることで、そのポインタは「文字列を入れる配列」と同じように扱うことができます。「[]の付いていない配列はポインタになる」と説明しましたが、逆にポインタは[]を付けることで配列と同じ扱いになります。(参考:ポインタと配列)。ですので、これまでと同じようにstrcpy()関数でコピーすることができます。
最後に、借りていたこのメモリ領域を返します。
普通の変数は、関数が終了したりしてスコープから外れれば自動的に削除されますが、malloc()関数で借りたメモリ領域は、自分で返さないと借りっぱなしになってしまいます。
それを避けるため、malloc()関数で借りていたメモリ領域を返す関数が、free()関数です。このランタイムライブラリの関数にアドレスを渡すことで、借りていた領域を返却し、Windowsはその領域を他の変数のために使用したりすることができるようになるわけです。
ちなみにfree()関数で領域を返さないと、その領域は借りっぱなしになってしまいます。
しかも、ポインタ(つまりアドレスを入れた変数)はスコープから外れると消えてしまいます。つまりその領域は「借りたけど返さず、しかも操作をするためのアドレスも手元にない」という状態になってしまいます。これをメモリリークと言います。こうなってしまうと、そのメモリ領域は使うことのできない死んだ状態になってしまいますので、必ずfree()関数で返却するようにしてください。
で、CStringクラスは、このmalloc()関数を使用して文字列を入れる領域を取得しています。そのため、大きな文字列を入れることができますし、文字列の追加もできるわけです。
ちなみに文字列の追加時には、追加後の文字列が入る領域を確保して、そこに元の文字列と追加する文字列をコピーしてから、元の領域のポインタと置き換えるという方法で行います。配列でこのようなことを行うとかなり面倒なので、CStringクラスを使った方がいいでしょう。
CStringとchar *
最後に、CStringクラスと通常の文字列型との関係を見ておきましょう。
strcpy()関数を例に考えてみましょう。サンプルプログラム7で説明したように、文字列を引数に取る関数は、char *型かconst char *型が引数に指定されています。
「constの有無」で説明したように、char *型は「書き込み用」、const char *型は「読み取り用」となっています。strcpy()関数は、第1引数が前者、第2引数が後者なので、第2引数から第1引数へと文字列がコピーされるんだ、ということをすでに説明しました。
CStringクラスの変数をこのstrcpy()関数に渡す場合、このどちらに渡すかでまったく違うという点に注意してください。前者の場合は文字列を入れるための準備が必要ですし、後者の場合には中に閉じこめられている文字列を取り出す方法を知る必要があります。この2つの方法について説明します。
まずは、const char *型にCStringクラスの変数を渡す場合から。
char pchTo[32];
// CStringクラスの変数を宣言して、
// 文字列を入れておきます。
CString cFromString = "ABC";
// strcpy()関数でコピーします。
// const char *型へは、CStringクラスの変数を
// そのまま渡すことができ、そうすることで
// 中の文字列へのポインタを渡すことができます。
strcpy( pchTo, cFromString );
// 出力します。
TRACE( "%s\n", pchTo );
// ABC
// コピー先の配列を先に用意しておきます。 char pchTo[32]; // CStringクラスの変数を宣言して、 // 文字列を入れておきます。 CString cFromString = "ABC"; // strcpy()関数でコピーします。 // const char *型へは、CStringクラスの変数を // そのまま渡すことができ、そうすることで // 中の文字列へのポインタを渡すことができます。 strcpy( pchTo, cFromString ); // 出力します。 TRACE( "%s\n", pchTo ); // ABC
このプログラムでは、CStringクラスの変数cFromStringに文字列を入れておき、strcpy()関数の第2引数に渡しています。
実は、const char *型へはCStringクラスの変数をそのまま渡すことができます。
クラスには「型変換演算子メンバ関数」という機能があります。これはメンバ関数の一種で、特定の型にキャストするよう求められた時、自動的に呼び出されるメンバ関数です。
CStringクラスには「const char *型へのキャスト」を求められたときに自動的に呼び出される型変換演算子メンバ関数が用意されています(正式なメンバ関数名は「operator LPCTSTR()」となりますので、CStringクラスのリファレンスでこのメンバ関数を探してみてください)。このメンバ関数は、CStringクラスの変数が中に持っている文字列へのポインタを返します。strcpy()関数は第2引数でこれを受け取り、文字列のコピー元として使用するわけです。

この機能のおかげで、const char *型にはそのまま渡すことができます。
では逆に、char *型に渡す場合にはどうすればいいのかというと、これは少々面倒です。
CStringクラスは短い文字列も長い文字列も格納できます。前述したmalloc()関数を使用して、適切なサイズの領域を確保して、そこに文字列を書き込むわけです。
さて、char *型に渡す、たとえばstrcpy()関数の第1引数に渡す場合、それはどういうことか考えてみましょう。図5から分かるとおり、渡すのは「コピー先の領域のアドレス」ということになります。
ところが、CStringクラスは文字列の長さにあわせて領域のサイズが変化します。ということは、もし中に入っている文字列がとても短かったら、strcpy()関数でコピーするときに領域を超えてコピーしてしまうかもしれません。
文字列が格納できるだけのサイズを持っているのか、ということが「中に入っている文字列の長さで決まる」ということになってしまうわけで、じゃあstrcpy()関数に渡す前にながーい文字列を入れておいて領域を確保しておけばいいのかというと、これから文字列をコピーするのにその前に無駄な文字列をコピーしておく、というのも変な話です。
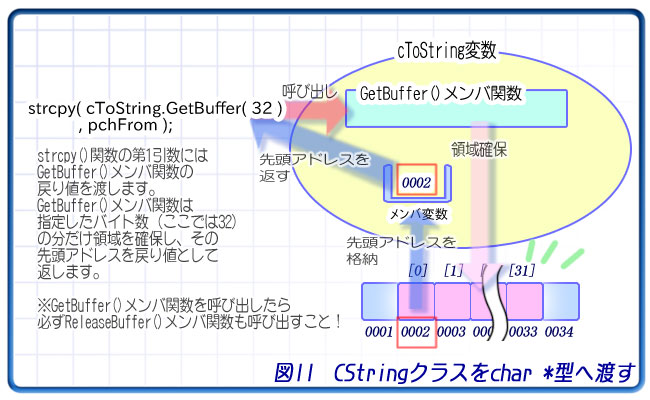
そこで、CStringクラスには「サイズを指定して領域を確保するメンバ関数」が用意されています。それはGetBuffer()メンバ関数です。
char pchFrom[] = "ABC";
// CStringクラスの変数を宣言します。
CString cToString;
// strcpy()関数でコピーします。
// char *型へはGetBuffer()メンバ関数の戻り値を渡します。
// その際、引数には領域のサイズ(文字数)を指定します。
strcpy( cToString.GetBuffer( 32 ), pchFrom );
// GetBuffer()メンバ関数を呼び出したら、必ず
// ReleaseBuffer()関数を呼び出します。
cToString.ReleaseBuffer();
// 出力します。
TRACE( "%s\n", cToString );
// ABC
// コピー元の文字列を先に用意しておきます。 char pchFrom[] = "ABC"; // CStringクラスの変数を宣言します。 CString cToString; // strcpy()関数でコピーします。 // char *型へはGetBuffer()メンバ関数の戻り値を渡します。 // その際、引数には領域のサイズ(文字数)を指定します。 strcpy( cToString.GetBuffer( 32 ), pchFrom ); // GetBuffer()メンバ関数を呼び出したら、必ず // ReleaseBuffer()関数を呼び出します。 cToString.ReleaseBuffer(); // 出力します。 TRACE( "%s\n", cToString ); // ABC
このプログラムは、CStringクラスの変数を宣言し、それをstrcpy()関数の第1引数、つまりコピー先として渡しています。
渡す時にはそのまま渡さず、GetBuffer()メンバ関数を呼び出して、その戻り値を渡しています。
CStringクラスのGetBuffer()メンバ関数は「文字列を入れておくための好きなサイズの領域を確保する」メンバ関数です。引数には領域のサイズを指定します。そうすると、そのサイズだけ領域を確保し、その先頭アドレスを戻り値として返します(ちなみに終端文字の分は勝手に増やしてくれます。たとえば"ABC"をかっちり入れたい場合は3を渡せば大丈夫です)。
このアドレスがstrcpy()関数の第1引数に渡されるので、strcpy()関数はそのアドレスが指し示す先を「コピー先の配列」とみなして文字列をコピーします。このように、GetBuffer()メンバ関数が返したアドレスは、まるでmalloc()関数で確保した領域を指すポインタのようになっているので、その領域を配列のように使うことができるわけです。
最後に注意して欲しいのは、文字列のコピーが完了したら、必ずReleaseBuffer()メンバ関数を呼び出す必要があるという点です。これはGetBuffer()メンバ関数の後処理を行うもので、GetBuffer()メンバ関数を呼び出したら必ずReleaseBuffer()メンバ関数も呼び出してください。
このように、char *型に渡す場合にはGetBuffer()メンバ関数とReleaseBuffer()メンバ関数を使用します。const char *型よりは面倒ですが、CStringクラスを様々なランタイムライブラリで使用できるようになるので我慢しましょう。
最後に、APIの場合について。
APIの引数は、文字列を渡すときにはLPCTSTR型、受け取る時にはLPTSTR型が指定されています。
ですが、これまで説明してきたとおり、LPCTSTR型はconst char *型、LPTSTR型はchar *型と同じなので、LPCTSTR型にはCStringクラスの変数をそのまま渡し、LPTSTR型にはGetBuffer()メンバ関数を呼び出してその戻り値を渡すようにすればいいわけです。
試しに、strcpy()関数のAPI版である、lstrcpy()関数で試してみましょう。lstrcpy()関数は、第1引数がLPTSTR型、第2引数がLPCTSTR型です。
// 文字列を入れておきます。
CString cFromString = "ABC";
// CStringクラスの変数を宣言します。
CString cToString;
// lstrcpy()関数でコピーします。
// LPTSTR型へはGetBuffer()メンバ関数の戻り値を渡します。
// その際、引数には領域のサイズ(文字数)を指定します。
// LPCTSTR型へは、CStringクラスの変数を
// そのまま渡すことができ、そうすることで
// 中の文字列へのポインタを渡すことができます。
lstrcpy( cToString.GetBuffer( 32 ), cFromString );
// GetBuffer()メンバ関数を呼び出したら、必ず
// ReleaseBuffer()関数を呼び出します。
cToString.ReleaseBuffer();
// 出力します。
TRACE( "%s\n", cToString );
// ABC
// CStringクラスの変数を宣言して、 // 文字列を入れておきます。 CString cFromString = "ABC"; // CStringクラスの変数を宣言します。 CString cToString; // lstrcpy()関数でコピーします。 // LPTSTR型へはGetBuffer()メンバ関数の戻り値を渡します。 // その際、引数には領域のサイズ(文字数)を指定します。 // LPCTSTR型へは、CStringクラスの変数を // そのまま渡すことができ、そうすることで // 中の文字列へのポインタを渡すことができます。 lstrcpy( cToString.GetBuffer( 32 ), cFromString ); // GetBuffer()メンバ関数を呼び出したら、必ず // ReleaseBuffer()関数を呼び出します。 cToString.ReleaseBuffer(); // 出力します。 TRACE( "%s\n", cToString ); // ABC
このプログラムでは、サンプルプログラム19とサンプルプログラム20と同じ処理を、APIのlstrcpy()関数で行っています。lstrcpy()関数の第1引数はLPTSTR、第2引数はLPCTSTR型ですが、このようにchar *型、const char *型と同じ方法で渡すことができます。
ちなみに、この時使用されるGetBuffer()メンバ関数と型変換演算子メンバ関数(operator LPCTSTR())は、どちらも「ダブルバイト文字とUnicodeの切り替え機能」に対応しています。前者の戻り値の型はLPTSTR、後者の戻り値の型はLPCTSTRとなっています(ちなみにGetBuffer()メンバ関数の引数は「文字数」を指定します。バイト数ではないのでUnicode版でもwchar_t倍しなくても大丈夫です)。
CStringクラスはとても便利なクラスです。MFCが使えるのであれば、積極的に利用しましょう。
で、その際に「あれ、ランタイムライブラリに使う時ってどうすればいいんだろう」「LPTSTRって何? LPCTSTRって何??」といった、CStringクラスを使う際の疑問があればこのページを再びお読みいただければと思います。