ポインタと配列
|
配列とポインタは切っても切れない関係です。それに、ポインタというものを理解する上でとても重要な存在でもあります。というわけで、ポインタへの理解を深めるために、今回は配列について見ていきましょう。
|
|
配列とは
配列はひとつの型の変数を複数作成して、まとめて扱いたいときに使用します。
たとえば出席簿。30人の生徒の身長を扱いたい場合、ひとつひとつint型の変数を作成していてはきりがありません。こんなときに配列を使用すると、30個のint型変数をひとまとめにすることができます。具体的には次のような感じに。
|
int iAry[30]; //配列の宣言。
iAry[0] = 150;
iAry[1] = 160;
iAry[2] = 170;
// 以下続く。
// こんな風にも宣言できます。
int iAry2[] = { 180, 190, 200 };
TRACE( "1: %d, 2: %d, 3: %d\n", iAry2[0], iAry2[1], iAry2[2] );
// 1: 180, 2: 190, 3: 200
配列の宣言は次のようにします。
変数の型 変数名[要素の数];
上の最初の例では、int型の変数が30個作成されます。この変数ひとつひとつにアクセスするときには、「何番目の変数」かを[]に指定します。
ここで重要なのは、この指定する数はゼロから要素数−1までということです。上の最初の例では要素数が30なので、0〜29までの値を指定します。この違いを忘れてiAry[30] = 1;とかしないようにしましょう。実際にはエラーが発生しないことが多いので、特に注意。
また、配列は{}を使うことで宣言と初期化を同時にすることができます。この場合には初期化した要素の数が、そのまま要素数になります。上の後の例ではint iAry2[3] ;と同じことになります。
|
|
配列のなかみ
配列の中では、各要素が並べられています。「並べられている」というのは「メモリ上で」という意味です。次のコードを試してみてください。
|
int iAry[3]; //配列の宣言。
TRACE( "&iAry[0]: %X, &iAry[1]: %X, &iAry[2]: %X\n"
, &iAry[0], &iAry[1], &iAry[2] );
// &iAry[0]: 63F5E0, &iAry[1]: 63F5E4, &iAry[2]: 63F5E8
「整数のなかみ(前編)」で解説したように、変数の各ビットはメモリ上の「オセロのコマ」のような形で格納されています。このオセロのコマは8個単位、つまりバイト単位でまとめられ、そのひとつひとつに 「住所」として32ビットの整数値が割り当てられています。これを アドレスといいます。前回ポインタに格納していたのは、この「オセロのコマ×8」のインデックスナンバーということです。
それをふまえて、上の例を試してみてください。アドレスは変数名の頭に &を付けることで取得できます。上の例では、まず3つの要素のアドレスを取得して表示しています(アドレスは実行するごとに変わります)。この結果を見てください、何か気づきませんか?
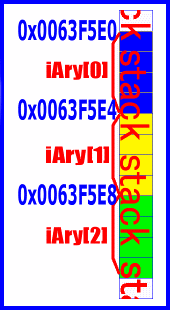 そう、各アドレスは4バイトずつ離れています。4バイト=32ビット、つまりint型の分だけ離れているのです。もし要素の型をWORDにしたら2バイトずつ、charにしたら1バイトずつ差が現れることになります。
そう、各アドレスは4バイトずつ離れています。4バイト=32ビット、つまりint型の分だけ離れているのです。もし要素の型をWORDにしたら2バイトずつ、charにしたら1バイトずつ差が現れることになります。
このことから、配列は各要素がメモリ上に並べられていることが分かると思います。隙間なく、その型のサイズ分ずつメモリが確保されています。
このイメージを大切にしてください。配列だけでなく、変数の中身はすべてこのようにメモリ上で適当に並んでいます。変数のサイズだけ「オセロのコマ」が確保され、コマが8つ並ぶごとに「アドレス」が割り当てられています。つまり、変数が置かれた場所は、このアドレスによって確定できるということです。そう、このアドレスは、変数の住所なのです。同じものは同時にふたつ以上存在しないのです。
|
|
配列とポインタの密接な関係
前々回、前回と「参照渡し」について見てきましたが、その中では配列に触れていません。それは、配列が特殊だからです。以下のコードを試してみてください。
|
int iAry[3]; //配列の宣言。
TRACE( "iAry: %X, &iAry[0]: %X\n", iAry, &iAry[0] );
// iAry: 63F5E0, &iAry[0]: 63F5E0
int *pi = &iAry[0];
TRACE( "iAry: %X, pi: %X\n", iAry, pi );
// iAry: 63F5E0, pi: 63F5E0
要素インデックスの付いていない配列変数は、そのままで アドレスを表示します。そして、このアドレスは 1番目の要素と同じものです。
この「何も付いてない配列変数」の振る舞いは、後の方のコードを見れば分かるとおり ポインタと同じものです。ポインタは「アドレスを格納する変数」ですから、 &なしでアドレスを取得できます。これと同じことが、配列変数でもできてしまいます。つまり、 「何も付いてない配列変数」=「ポインタ」ということです。
さらに次のコードを見てください。
|
void Test3( int *p_piAry )
{
TRACE( "p_piAry[0]: %d\n", p_piAry[0] );
// p_piAry[0]: 1
p_piAry[2] = 3;
}
void Test2( int p_iAry[] )
{
TRACE( "p_iAry[0]: %d\n", p_iAry[0] );
// p_iAry[0]: 1
p_iAry[1] = 2;
}
void Test1()
{
int iAry[3];
iAry[0] = 1;
Test2( iAry );
Test3( iAry );
TRACE( "iAry[1]: %d, iAry[2]: %d\n", iAry[1], iAry[2] );
// iAry[1]: 2, iAry[2]: 3
}
Test2()と Test3()の引数は、どちらも ポインタを意味します。 「配列を渡す」という考え方なら Test2()のような引数の方が合いそうですが、 「何も付いてない配列=ポインタ」を考えれば Test3()のように単純にポインタで渡した方が分かりやすい気もします。
渡すのはいずれもポインタです。ですから、 Test2()と Test3()がアクセスするのは Test1()の iAry[]の各要素です。ですから、 Test1()に戻ってきてから中身を確認すれば、ちゃんと各関数での処理が反映されているわけです。
ここでTest3()に注目してください。この中ではポインタを配列と同様に扱っています。つまり、「ポインタ」=「何も付いてない配列」だということです。
要するに、「何も付いてない配列とポインタはほとんど同じもの」ということです。ポインタに[]を使えば配列と同様にアクセスできますし、また配列から[]を取り除けばポインタのように機能します(実際にはちょっと違います。それはそれはあとで)。
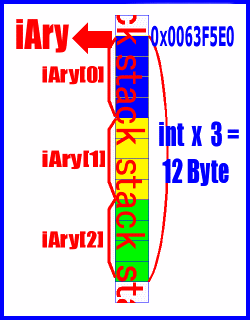 まとめてみましょう。「配列」は、「型のサイズ×要素数」だけメモリを確保します。そして、その先頭アドレスが「何も付いてない配列」に入ります。
まとめてみましょう。「配列」は、「型のサイズ×要素数」だけメモリを確保します。そして、その先頭アドレスが「何も付いてない配列」に入ります。
この「何も付いてない配列」か、先頭アドレスの入ったポインタ(つまりこのふたつは同じ機能を持ちます)に[要素インデックス]を渡すと、「先頭アドレス+型のサイズ×インデックス」から「先頭アドレス+型のサイズ×(インデックス+1)」の間を「要素の型の変数」として扱います。
つまり「配列」は、メモリの確保+その先頭ポインタの格納という機能を持ったポインタということです。また[]は「配列の機能」ではなく「ポインタの機能」ということになります。
ここで重要なのは配列を使う=ポインタを使うということです。何を今さら、と思うかもしれませんが、たとえできる限りポインタの代わりに参照を使うことにしたとしても、配列を使った時点でポインタから逃れられなくなってしまうのです!!
これはとても重要な問題です。バグを減らすコツとして「いろいろな方法がある場合にはその中からひとつに絞る」というものがあります。関数の参照渡しで参照のみを使いたい、と思っていても、「配列を渡す」ということは「ポインタを使う」ことになってしまうのです。参照とポインタを同時に使うと混乱やバグの種になりかねません。
ま、この辺の解決は先送りして、もう少し配列とポインタについて見ておきましょう。
|
|
ポインタの移動
[要素インデックス]を使うと、ポインタが指すメモリ領域の中の特定の領域にアクセスできる方法を説明しました。これとは逆に、「配列の各要素にポインタを用いてアクセスする方法」を見てみましょう。
|
int iAry[3];
iAry[0] = 1;
iAry[1] = 2;
iAry[2] = 3;
int *pi = iAry;
TRACE( "*( pi + 0 ): %d, *( pi + 1 ): %d, *( pi + 2 ): %d\n"
, *pi, *( pi + 1 ), *( pi + 2 ) );
// *( pi + 0 ): 1, *( pi + 1 ): 2, *( pi + 2 ): 3
配列の先頭ポインタを他のポインタ変数に渡すところまではいいですね。このポインタを使って、配列の各要素を取得します。ポインタをそのまま使えばもちろん第1要素。次の要素を取得するということで1を足して2番目の要素を取得、また足して3番目を……。
あれ、と思ったでしょう。アドレスは 32ビット整数でした。もちろんポインタ変数にもこの整数値が入っています。でも、配列の各要素は4バイトずつ離れてるはず。4足さなきゃいけないんじゃないの?
実はこれは、ポインタだけの特殊性です。上のコードの次に以下のコードを継ぎ足してください。
|
TRACE( "&iAry[0]: %X, &iAry[1]: %X, &iAry[2]: %X\n"
, &iAry[0], &iAry[1], &iAry[2] );
// &iAry[0]: 63F5D0, &iAry[1]: 63F5D4, &iAry[2]: 63F5D8
TRACE( "pi + 0: %X, pi + 1: %X, pi + 2: %X\n"
, pi, pi + 1, pi + 2 );
// pi + 0: 63F5D0, pi + 1: 63F5D4, pi + 2: 63F5D8
|
配列の各要素のアドレスと、ポインタに1と2を加えたものを比べてみると、実は同じなのです。これはどういうことかというと、「ポインタ+n」という演算は、バイト単位では「ポインタ+n×型のバイト数」ということなのです。そのため、ポインタの方もちゃんと4バイトずつ増えているというわけです。
これはポインタだけの特殊な機能です。と言うよりは、配列としての機能を重要視したものと考えた方がいいのかもしれません。[要素インデックス]を用いた方法と、ポインタの足し算は「表現方法が違うだけ」と言えるでしょう。
|
|
配列の大きさは?
「ポインタ」=「何も付いてない配列」と前述しましたが、実はふたつの部分で違いがあります。
まず「何も付いてない配列」は定数値だということです。たとえば次のようなことはできません。
|
int iAry[10];
++iAry; //コンパイルエラー。
|
このように、一度作成した配列はアドレスを変更できません。当たり前といえば当たり前のことですが。
さて、もうひとつ違いがあります。それはsizeof()の結果です。
|
int iAry[10];
int *piAry = iAry;
TRACE( "iAry: %d, piAry: %d, *piAry: %d\n"
, sizeof( iAry ), sizeof( piAry ), sizeof( *piAry ) );
// iAry: 40, piAry: 4, *piAry: 4
|
sizeof()は「変数のサイズ」を求めるものなので、32ビットのポインタは当然4バイトと返されます。が、「何も付いてないポインタ」はポインタのサイズではなく「配列の要素数×要素のサイズ」が返ってきます。この機能のおかげで、配列は簡単にその要素数を求められます。
これは逆に、ポインタを通しては配列のサイズが判らないということです。これが次回説明する「文字列操作」で大きな問題になってきます。
(この部分追加しました。指摘してくれた方ありがとう!!)
|
ポインタと参照の違い2
以上のように、ポインタはある意味「配列と同じ機能を持っている」と言えます。また、「アドレス」というデータを重要視してもいます。ポインタはフレキシブルで、様々な使い道のあるシステムです。
けれども、その自由度が命取りになる場合もありますし、また扱いが他の変数とまったく別なのでめんどくさいという問題もあります。そこでC++が作られたときに、ポインタの中で「関数の引数として使う」ことに特に特化したものを 「参照」として加えたのです。
けれども、今回解説した配列のように、ふつうのプログラミングで欠かせない部分にもポインタは存在します。そのため、できるだけ使いたくなくても使わざるを得ないと言えるでしょう。
次回は、その使わざるを得ない部分、配列のもっとも多い使い道であろうと思われる「文字列操作」について見ていくことにしましょう。
|