文字列操作
この辺から実践的な内容に入っていきます。あと、実は、今回解説する部分の多くは「MFCユーザーのためのAPI講座」の ポインタと文字列とCStringと同じものです。ので、そちらのページもご覧ください。
|
「変数のなかみ」ふたたび
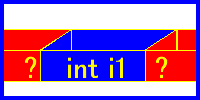 以前説明したように、宣言された変数はメモリ上にそのサイズ分だけ確保されます。たとえばint型なら、32ビット分の領域がサイズに確保されます。
以前説明したように、宣言された変数はメモリ上にそのサイズ分だけ確保されます。たとえばint型なら、32ビット分の領域がサイズに確保されます。
逆に言えば、使うことができるのはその確保された領域のみということです。たとえば、確保された領域の両隣が「直前・直後に宣言した変数」だということは保証されていません。もしかしたらアプリケーションの重要なデータを含む領域かもしれませんし、他のアプリケーションが使用しているかもしれません。
アプリケーションは確保されたビットの並びを変え、その「組み合わせ」を任意のデータとして割り当てて使用します。たとえばintならOxFFFFFFFFを-1とするように。
そして、使用できるのはその組み合わせの範囲内だけです。OxFFFFFFFFFみたいな値をintに入れることはできません。はみ出して、他の変数領域に踏み行ってしまいます。
また、すぐ隣が空いているとは限らないため、一度割り当てられた領域は自由にサイズを変えられません。サイズを変えたい場合には新たに領域を確保し、データをコピーして、元の変数を削除する、といった形を取らなければなりません(これについては次回説明します)。
以上のような制約が、C言語に「文字列型」というものを作らせませんでした。
単語、文字列、文章は文字の数がまったく特定できません。1文字かもしれませんし、400文字かもしれません。これらのどの文字数も入るような変数を作るとなると、ムダが必ず生じる上、どうしても限界が出てきてしまいます。
また、可変長型を作成することをC言語は嫌いました。C言語は「ポインタ」というメモリを操作する方法を持っています。また同時に、機種やOSによってメモリモデルは変わってきます。そのため、言語として可変長型を作ってしまうよりも、ポインタを利用してもらってコードの側で処理してもらうべきだと考えられました。
その結果、C言語には文字列型は作られなかったのです。
|
文字と整数
とはいえ、「プログラム」というものが人のためにある以上、文字列というものを扱えないということが不便なことには代わりありません。そこで、C言語では 「整数配列」というものを利用して文字列型の代わりにしました。
int型がそうだったように、変数の中に入っているように見える「数字」は実際には見せかけの存在です。変数の中にあるのは「ビットの並び」で、それをどう解釈するかはアプリケーション側の判断に任されています。同じ0xFFFFFFFFでも、それをどう解釈するかは型や関数によって変わってきます。
では、その「見せかけ」をさらにひねって、「0110というビット並びをAと見るようにしよう」みたいなことを考えたのが、「文字列型」の元です。整数値と同じように、型や関数を通すことで特定の「整数値」を「文字」へと変換すれば、整数値で文字を表せ、その配列で文字列を表せることになります。
実際にこれをコードで確かめてみましょう。
|
TRACE( "'A': 0x%X, 0x41: '%C'\n", 'A', 0x41 );
// 'A': 0x41, 0x41: 'A'
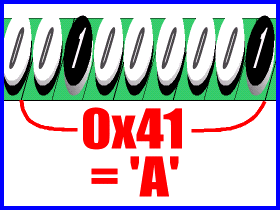 アルファベット1文字1文字にはそれぞれ整数値が割り当てられています。この割り当てはあらかじめ決められていて、「ASCII(American Standard Code for Information Interchange)」と呼ばれています。文字をこの整数値へと変換する場合には「’(アポストロフィ)」で囲みます。
アルファベット1文字1文字にはそれぞれ整数値が割り当てられています。この割り当てはあらかじめ決められていて、「ASCII(American Standard Code for Information Interchange)」と呼ばれています。文字をこの整数値へと変換する場合には「’(アポストロフィ)」で囲みます。
上の例で見れば判るとおり、「A」という文字は「0x41」という整数値が割り当てられています。また、ASCIIコードは「文字」に割り当てられているので、小文字の「a」には別の整数値「0x61」が割り当てられてますし、また「#」のような記号や「8」のような数字にも整数値が割り当てられています。
|
|
char型の登場
コンピューターは「英語圏」から生まれ、発展していきました。これが日本や中国、いやドイツやフランスからだったとしても、コンピューターの歴史は変わっていたかもしれません。が、偶然にもコンピューターは「もっとも文字数の少ない言語のひとつ」が使われている場所で発展していったのです。
「文字配列」はもちろん「文字型」の配列ですから、もし「文字型」が無駄に大きいと配列の要素数、つまり文字数の分だけムダが生まれてしまいます。そのため、先ほどの「文字を意味する整数値」を格納するための「文字型」はできるだけ小さい方がいいことになります。
初めはint型が考えられていました。現在も「1文字」を表すときにint型を使うことが良くあります。が、実際に文字の種類を数えてみると、数字、記号、アルファベットの大文字小文字合わせても128種類以下くらいにしかなりませんでした。OSなどによって型の変わるintよりは、よりムダのない文字型を作るべきだと思われました。
そこで8ビット=1バイトというサイズの文字型、charが作られました。1バイトなら256通りの組み合わせが作れるので、256種類の文字を表現できます。これなら十分と考えられました。
(ただし、ものによってはサイズが「7ビット」とさらにケチっているものもあります。これが後々問題になるのですが、とりあえず今は「8ビット」と考えておいてください)
実際にchar型は、こんな風に使います。
|
char chA = 'A';
char ch41 = 0x41;
TRACE( "chA: 0x%X, ch41: '%C'\n", chA, ch41 );
// chA: 0x41, ch41: 'A'
if( chA == ch41 )
TRACE0( "Hit!!\n" );
// Hit!!
|
このように、charは1バイトの整数型です。ですから、基本的にはintとほぼ同じと考えていいでしょう。サイズがだいぶ小さくなっているくらいの違いです。
さて、文字型が決まったところで、この配列を作成して「文字列」を表してみましょう。
|
|
文字型の配列
文字型の配列は、前回と同じように、ごく普通に配列として作成します。特に難しいことはありません。
|
char chTest[32]; //文字型の配列。
chTest[0] = 'A'; //「A」1文字を入れます。
chTest[1] = 'B'; //「B」1文字を入れます。
chTest[2] = 'C'; //「C」1文字を入れます。
chTest[3] = '\0'; //NULL文字を入れます。
TRACE( "chTest: %s\n", chTest );
 このように、char型の配列として文字列を作製し、配列の要素ひとつひとつに文字が入るという形になります。
このように、char型の配列として文字列を作製し、配列の要素ひとつひとつに文字が入るという形になります。
通常、配列の長さと、入っている文字列の長さは一致しません。そのため、「どこが文字列の終わりか」を示す文字、NULL文字というものを最後に入れておきます。文字としては「\0」(98系は「¥0」、DOS/V系は「\0」)で、これはASCIIコードでは0になっています。ヘルプなどでよく見る「NULL で終わる文字列」や「null-terminated string」は、この文字が最後に入れられている文字列のことです。
また、この「NULL文字」も立派な文字のひとつだということを忘れないでください。たとえば、次のようなコードは間違いです。
|
char chTest[3]; //3文字分しか確保してない。
chTest[0] = 'A';
chTest[1] = 'B';
chTest[2] = 'C'; //ここまではOK
chTest[3] = '\0'; //配列をオーバー!
|
と、配列の要素数はNULL文字の分もちゃんと確保しておく必要があります。特に「要素数-1=要素インデックスの上限」だということをちゃんと認識していないと起こしやすいまちがいです。
これを防ぐ意味合いもあって、文字型の配列は次のように宣言と初期化を同時にすることができます。
|
char chTest[] = "ABC";
// char chTest[] = { 'A', 'B', 'C', '\0' }; と同じ。
TRACE( "sizeof: %d, chTest[3]: %X\n"
, sizeof( chTest ), chTest[3] );
// sizeof: 4, chTest[3]: 0
|
このようにすると、自動的にchar型×4の配列が作製され、各要素に文字が入れられた上、ちゃんと最後にNULL文字が入れられます。ダブルクォーテーションで囲った文字列の場合には、「最後にNULL文字が入っている」と見なされるので、この場合にも最後にNULL文字が入るというわけです。
|
|
文字列操作系関数
で、実はここでのダブルクォーテーションの使い方は非常に珍しいものです。このような形は「配列の宣言&初期化」の時しか使えません。つまり、前回説明した{}(中カッコ)を使った宣言&初期化の違う書き方ということです。ということは、次のようなことはできないということになります。
|
char chTest[32]; //文字型の配列。
chTest = "ABC"; //ダメよん。
|
{}のときと同じように、ダブルクォーテーションが使えるのも「宣言と初期化を同時に行ったとき」のみです。ですから、あとでこのように文字列を格納することはできません。
ちなみに次の例で判るように、ダブルクォーテーションで囲んだ文字列は、通常「一時的な文字配列へのポインタ」として機能します。こちらの方が普通の使い方です。
では文字列のコピーにはどうするのかというと、ちゃんとそのための関数が用意されているんです。
|
char chTest[32]; //文字型の配列。
strcpy( chTest, "ABC" ); //文字列のコピー。
TRACE( "chTest: %s\n", chTest );
// chTest: ABC
strcpy()という関数は、 ランタイムライブラリと呼ばれるものに含まれる関数で、文字列をコピーしてくれます。
もうおわかりの通り、C言語は「できるだけプログラマーの自由に任せる」言語です。そのため、ポインタのようなコンピューターのアーキテクチャーに直接触れるような機能を持ち、また余分な機能を勝手に作ってお仕着せたりはしません。
が、逆にそれはあまりに不便すぎないか、初心者に辛すぎないかということで標準的な関数ライブラリが作られることになりました。そこで「ANSI(American National Standards Institute)」という組織が作成した関数ライブラリが「ランタイムライブラリ」と呼ばれるものなのです。
ランタイムライブラリにはこれ以外にも様々な関数が存在します。それに、VCのみでしか使われない関数も多く存在します。関数名の前に_(アンダーライン)が引かれているものがそうです。
|
|
文字列操作関数の作り方
ここまで配列の作り方や操作方法、それと文字列との関係を見てきたので、ある程度「文字列操作がどんな感じか」は分かったと思います。でも実際に「どう関数を作ればいいのか」ということは分かりにくいと思います。
そこで、具体的に前述のstrcpy()のソースコードを見ながら、どういう設計を行えばいいのか考えてみましょう。
ちなみにソースコードはVCのCD-ROMの「DEVSTUDIO\VC\CRT\SRC\STRCAT.C」にあります。また、同じフォルダの中に他のランタイム関数のソースがあるので、それらも参考にしてみてください。「こういうプログラム」を組んだことのない方には結構新鮮なんじゃないかなと思います。
では、実際のコードを見てみましょう。
|
char * __cdecl strcpy(char * dst, const char * src)
{
char * cp = dst;
while( *cp++ = *src++ )
; /* Copy src over dst */
return( dst );
}
まず引数について見てください。両方とも char型のポインタになっています。この型を使うことで、文字列の入った配列をそのまま渡すことができます。このように、文字列はほとんどポインタを通して操作します。
また、第2引数に constが付いていることを確認してください。こうすることで、第2引数の文字配列は 「操作されない」ということになります。
これは逆の見方をすれば、 「コピーは第2引数から第1引数へと行われる」ということを意味していると言えます。プロトタイプ宣言を見れば一目瞭然、ということを考えてもこのようにまめに constを付けることが重要になります。
次に第1引数のポインタをコピーします。第1引数は後で戻り値として返すため、変更できないからです。
その後、whileを使って1文字ずつコピーしていきます。これは単なる整数値どうしのコピーです。コピーしたら両ポインタともインクリメントして、次の文字を指すようにします。
コピーした文字がNULL文字だったとき、これは整数値ではゼロなので、whileから抜け出ます。これで、文字列のコピーは終了です。
最後に第1引数のポインタを返して終了です。なぜわざわざポインタを返すのか、戻り値がポインタになってるのかというと、次のような使い方をするからです。
|
strcpy( chTest2, strcpy( chTest, "ABC" ) ); //2段コピー。
このように立て続けに2回コピーしたいときに使用します。この機能は特に他の文字列操作関数で有効に利用できます。
(あと、戻り値の型の __cdeclについては、「DLL」の「 DLLを作ろう!(関数編)」の「装飾名」について見てください)
このように、ランタイムライブラリの関数は結構簡単にできています。こういった関数を参考にすれば、自分で文字列操作関数を作るのも難しくないでしょう。
が、実は注意して欲しいことがあります。
|
|
サイズのチェック
まず、次の「間違った」コードを見てください。
|
char chTest[3]; //要素数3。
strcpy( chTest, "ABCDEFG" ); //文字数8。
 受け取る側の配列は3文字まで、なのに8文字もの文字列をコピーしてしまいます。おそらくこれはエラーが発生しないでしょう。そのため2重にやっかいです。
受け取る側の配列は3文字まで、なのに8文字もの文字列をコピーしてしまいます。おそらくこれはエラーが発生しないでしょう。そのため2重にやっかいです。
こんなことができてしまうのは、strcpy()が全然チェックしないからです。でもこれはstrcpy()が悪いわけではないのです。strcpy()は「チェックしない」という設計方針で作られているからです。つまりチェックするのは使う側の仕事なのです。そのことがマニュアルにもちゃんと明記されています。
この問題は「関数の外にある文字配列へと文字列をコピーする」場合には必ず出てくるものです。そして、そういうことは非常によくあります。たとえば「出席番号を受け取ったらその名前を返す関数」みたいな感じで。
ところが、ここで前回最後に触れた問題が出てきます。配列はポインタとして渡されたあとはsizeof()で要素数を調べることができないのです。つまり、関数側で配列のサイズを知る方法はないのです。
そのため、基本的には「使う側の協力」が不可欠となります。たとえばstrcpy()のように「ちゃんと調べてから渡してください」のような乱暴なものもあります。
「要素数を指定」してもらうものもあります。たとえば「ここには要素数32以上の配列へのポインタを渡してください」みたいに書かれています。これは結構多く、特にウィンドウズ95でのパスの最大サイズを表すMAX_PATHを指定したものが多くあります。
そのほかに多いのが「配列の要素数を渡す」というものです。調べる方法がないのなら渡して欲しい、ということでこれがおそらく一番安全な方法でしょう。
|
ポインタと文字列
さて、ここまでで文字列について本当に簡単に見てみました。文字列操作は非常に奥が深いので、ごくごく浅く、基本となることを中心に解説しました。そしておそらく、ポインタについてもかなり理解が深まっているんじゃないかなと思います。
次回はさらにつっこんで、メモリの動的確保を見ていきたいと思います。次回をクリアすれば、ポインタについては(概念的には)ほぼマスターしたと考えていいでしょう。
あと、今回の講座では LPCTSTRや2バイト文字、 CStringには触れませんでした。これらについては「 ポインタと文字列とCString」をお読みください。
|