






ここまで、グローバル変数や構造体の問題点を見てきました。
では、オブジェクト指向プログラミングを使ってこの問題点を改善していきましょう。
「カプセル化」する
まずはオブジェクト指向プログラミングの一機能「カプセル化」を使ってみましょう。
具体的には、「3.5 GetterとSetter」で紹介したGetterとSetterを使って、フィールドを守ってみます。
/**
* フィールドをprivateにして、
* GetterとSetterを持つクラス。
*/
class Accessor
{
/**
* privateフィールドx3。
*/
private int data1;
private int data2;
private int data3;
/**
* そのGetterとSetter。
*/
public int getData1()
{
return data1;
}
public void setData1( int data1 )
{
this.data1 = data1;
}
public int getData2()
{
return data2;
}
public void setData2( int data2 )
{
this.data2 = data2;
}
public int getData3()
{
return data3;
}
public void setData3( int data3 )
{
this.data3 = data3;
}
}
/**
* 実行用クラス。このクラスを実行してください。
*/
class AccessorRunner
{
public static void main( String[] args )
{
// Accessorクラスのインスタンスを作ります。
Accessor ref = new Accessor();
// data1~data3フィールドに入れます。
ref.setData1( 35 );
ref.setData2( 45 );
ref.setData3( 55 );
// 平均を計算して出力します。
printAverage( ref );
}
/**
* 平均を計算します。
*/
public static void printAverage( Accessor accessor )
{
// 平均を計算して出力します。
int sum = 0;
sum += accessor.getData1();
sum += accessor.getData2();
sum += accessor.getData3();
// 平均を計算します。
int average = sum / 3;
System.out.println( average );
// 出力結果:
// 45
}
}
// AccessorRunner.java
/**
* フィールドをprivateにして、
* GetterとSetterを持つクラス。
*/
class Accessor
{
/**
* privateフィールドx3。
*/
private int data1;
private int data2;
private int data3;
/**
* そのGetterとSetter。
*/
public int getData1()
{
return data1;
}
public void setData1( int data1 )
{
this.data1 = data1;
}
public int getData2()
{
return data2;
}
public void setData2( int data2 )
{
this.data2 = data2;
}
public int getData3()
{
return data3;
}
public void setData3( int data3 )
{
this.data3 = data3;
}
}
/**
* 実行用クラス。このクラスを実行してください。
*/
class AccessorRunner
{
public static void main( String[] args )
{
// Accessorクラスのインスタンスを作ります。
Accessor ref = new Accessor();
// data1~data3フィールドに入れます。
ref.setData1( 35 );
ref.setData2( 45 );
ref.setData3( 55 );
// 平均を計算して出力します。
printAverage( ref );
}
/**
* 平均を計算します。
*/
public static void printAverage( Accessor accessor )
{
// 平均を計算して出力します。
int sum = 0;
sum += accessor.getData1();
sum += accessor.getData2();
sum += accessor.getData3();
// 平均を計算します。
int average = sum / 3;
System.out.println( average );
// 出力結果:
// 45
}
}
Accessorクラスは、すべてのフィールドがprivateになっています。
フィールドをprivateにすることで外から使えなくなります。
これを「カプセル化」と言います。インスタンスという「カプセル」の中にフィールドをかくまうことで、フィールドの値を安全に保つわけです。
フィールドをprivateにしただけだとフィールドを使えないので、値を入出力するためのGetter・Setterメソッドも追加します。
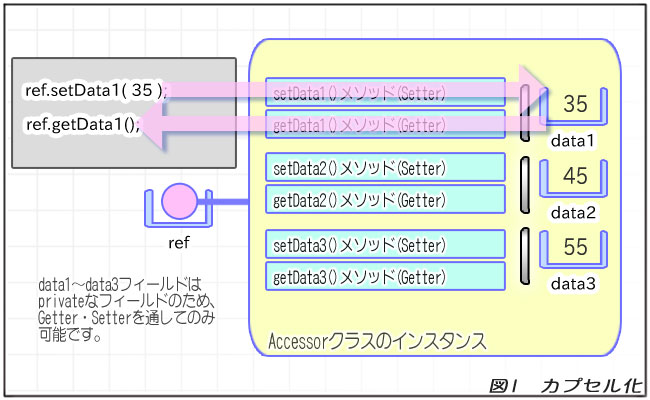
カプセル化を行うことで、フィールドを使うためには必ずメソッドを通ることになります。
これは非常に大事なことです。メソッドを通させることで、値のチェックを行ったり、ブレークポイントを置いていつどこから使われるか調べたり、その際に値を確認したりすることができるようになります。
また、メソッドを使ってフィールドを使うということは、自分でフィールドを使うということになります。
フィールドがpublicだった時には、フィールドを使うのは外のメソッドでした。
でも、カプセル化することで、フィールドを自分で使うことになります。
これが、オブジェクト指向プログラミングの第一歩になります。
ただ、まだちょっと安全じゃない部分があります。
まだ「単なるデータの貯蔵庫」という点は変わっていません。データを入れて取っておいて、そこから出し入れして使っているだけですから。
処理用メソッドを用意する
そこで、「データの出し入れをして使っている」箇所をメソッドにして、中に入れてしまいましょう。
/**
* データ3つを格納して、
* 平均を計算するクラス。
*/
class Average
{
/**
* privateフィールドx3。
*/
private int data1;
private int data2;
private int data3;
/**
* データを格納します。
*/
public void setDatas( int i1, int i2, int i3 )
{
data1 = i1;
data2 = i2;
data3 = i3;
}
/**
* 平均を計算します。
*/
public int getAverage()
{
// 平均を計算して出力します。
int sum = 0;
sum += data1;
sum += data2;
sum += data3;
// 平均を計算します。
int avr = sum / 3;
return avr;
}
}
/**
* 実行用クラス。このクラスを実行してください。
*/
class AverageRunner
{
public static void main( String[] args )
{
// Averageクラスのインスタンスを作ります。
Average ref = new Average();
// データを入れます。
ref.setDatas( 35, 45, 55 );
// 平均を計算して出力します。
int average = ref.getAverage();
System.out.println( average );
// 出力結果:
// 45
}
}
// AverageRunner.java
/**
* データ3つを格納して、
* 平均を計算するクラス。
*/
class Average
{
/**
* privateフィールドx3。
*/
private int data1;
private int data2;
private int data3;
/**
* データを格納します。
*/
public void setDatas( int i1, int i2, int i3 )
{
data1 = i1;
data2 = i2;
data3 = i3;
}
/**
* 平均を計算します。
*/
public int getAverage()
{
// 平均を計算して出力します。
int sum = 0;
sum += data1;
sum += data2;
sum += data3;
// 平均を計算します。
int avr = sum / 3;
return avr;
}
}
/**
* 実行用クラス。このクラスを実行してください。
*/
class AverageRunner
{
public static void main( String[] args )
{
// Averageクラスのインスタンスを作ります。
Average ref = new Average();
// データを入れます。
ref.setDatas( 35, 45, 55 );
// 平均を計算して出力します。
int average = ref.getAverage();
System.out.println( average );
// 出力結果:
// 45
}
}
Averageクラスは先ほどと同じようにprivateフィールドを3つ持っています。
でもメソッドが違います。GetterとSetterは持っていません。
代わりに、値をセットするsetDatas()メソッドと、平均値を計算するgetAverage()メソッドを持っています。
getAverage()メソッドは、これまでの例ではAverageRunnerクラスのprintAverage()メソッドだったものです。この計算処理をAverageクラスに持たせたわけです。
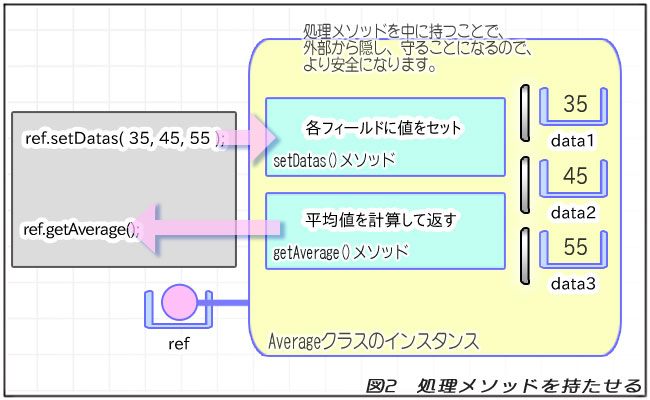
これまで「外」で行われていた「平均値の計算」を、「中」で行うようにしたのが今回の例です。
つまり、これまでが「データの貯蔵庫」だったのに対して、今回は「データを入れて、処理する」と、ちょっと高機能になったわけです。
このように変えることで、クラスでよりフィールドを管理することができます。
たとえば、これまではdata1~data3フィールドに対して自由にアクセスすることが実質的に可能でした。Getter・Setterメソッドを通しているとはいえ、そのフィールドの中に、目的とは全然関係ない値を入れることも可能だったわけです。
ところが、今回の修正でそれができなくなりました。値は「入れるだけ」ですし、使い方も「平均値の取得」しかできません。
つまり、クラスが「フィールドを使うメソッド」を持つことで、「適切な使い方だけが可能」になったわけです。変な使われ方をしないようになったわけですね。
ここまで来ればだいぶ安全になりましたが、もう一歩がんばってみましょう。
インタフェースと実装に分ける
最後に、クラスの各メソッドを呼び出すためのインタフェースを作りましょう。
/**
* データ3つを格納して、
* 平均を計算するインタフェース。
*/
interface AverageInterface
{
/**
* データを格納します。
*/
public void setDatas( int i1, int i2, int i3 );
/**
* 平均を計算します。
*/
public int getAverage();
}
/**
* データ3つを格納して、
* 平均を計算するクラス。
*/
class AverageImplements implements AverageInterface
{
/**
* privateフィールドx3。
*/
private int data1;
private int data2;
private int data3;
/**
* データを格納します。
*/
public void setDatas( int i1, int i2, int i3 )
{
data1 = i1;
data2 = i2;
data3 = i3;
}
/**
* 平均を計算します。
*/
public int getAverage()
{
// 平均を計算して出力します。
int sum = 0;
sum += data1;
sum += data2;
sum += data3;
// 平均を計算します。
int avr = sum / 3;
return avr;
}
}
/**
* 実行用クラス。このクラスを実行してください。
*/
class AverageInterfaceRunner
{
public static void main( String[] args )
{
// AverageInterfaceインタフェースの
// 実装クラスのインスタンスを取得します。
AverageInterface ref = getInstance();
// データを入れます。
ref.setDatas( 35, 45, 55 );
// 平均を計算して出力します。
int average = ref.getAverage();
System.out.println( average );
// 出力結果:
// 45
}
/**
* AverageInterfaceインタフェースの
* 実装クラスのインスタンスを返します。
*/
public static AverageInterface getInstance()
{
return new AverageImplements();
}
}
// AverageInterfaceRunner.java
/**
* データ3つを格納して、
* 平均を計算するインタフェース。
*/
interface AverageInterface
{
/**
* データを格納します。
*/
public void setDatas( int i1, int i2, int i3 );
/**
* 平均を計算します。
*/
public int getAverage();
}
/**
* データ3つを格納して、
* 平均を計算するクラス。
*/
class AverageImplements implements AverageInterface
{
/**
* privateフィールドx3。
*/
private int data1;
private int data2;
private int data3;
/**
* データを格納します。
*/
public void setDatas( int i1, int i2, int i3 )
{
data1 = i1;
data2 = i2;
data3 = i3;
}
/**
* 平均を計算します。
*/
public int getAverage()
{
// 平均を計算して出力します。
int sum = 0;
sum += data1;
sum += data2;
sum += data3;
// 平均を計算します。
int avr = sum / 3;
return avr;
}
}
/**
* 実行用クラス。このクラスを実行してください。
*/
class AverageInterfaceRunner
{
public static void main( String[] args )
{
// AverageInterfaceインタフェースの
// 実装クラスのインスタンスを取得します。
AverageInterface ref = getInstance();
// データを入れます。
ref.setDatas( 35, 45, 55 );
// 平均を計算して出力します。
int average = ref.getAverage();
System.out.println( average );
// 出力結果:
// 45
}
/**
* AverageInterfaceインタフェースの
* 実装クラスのインスタンスを返します。
*/
public static AverageInterface getInstance()
{
return new AverageImplements();
}
}
AverageInterfaceインタフェースは、先ほどのAverageクラスの各メソッドを抽象メソッドとして抜き出したものです。
AverageクラスはAverageImplementsクラスにして、AverageInterfaceインタフェースから実装しています。
AverageImplementsクラスのインスタンスはAverageInterfaceRunnerクラスのgetInstance()メソッドで作成し、参照を返しています。
さて、ここでmain()メソッドの視点で考えてみましょう。
setDatas()メソッドやgetAverage()メソッドはAverageInterfaceインタフェースの参照型変数を通して呼び出しています。
ということは、インスタンスがAverageImplementsクラスと分からない場合、「どのクラスのsetDatas()・getAverage()メソッドを呼び出しているかわからない」ということになります。
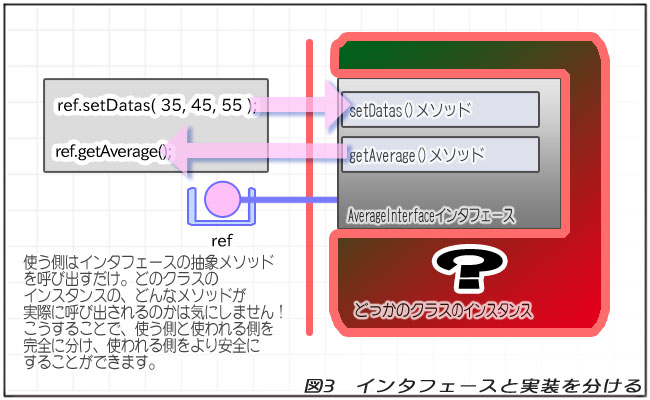
インタフェースを通してメソッドを呼び出すということは、実際に呼び出しているメソッドが「どのクラスのメソッドか分からない」ということです。
この時、使う側と使われる側が大きく隔たられます。
これまでは、使う側が使われる側をある程度知っていた状態で使っていました。少なくとも、どのクラスのインスタンスを使っていたかは分かっていたわけです。
でも、この例で、もし「new AverageImplements()」しているということが分からなかった場合、ref変数が指しているインスタンスが何クラスかわかりません。
そして、分からなくていいんです。
インスタンスのクラスは分からないし、setDatas()・getAverage()メソッドが内部でどんな処理をしているかも分かりません。
でも、setDatas()メソッドは値を格納し、getAverage()メソッドは平均値を返します。
それを満たしていれば問題ありません。
そして、内部がどうなっているのか分からない、ということはメリットです。
どんなクラスを使うのか、ということが分かっていると、そのクラスを「攻略」して、内部をより直接的に使われる可能性が出てきます。
直接的に使われることで、使われる側が望まない不適切な使い方をされるかもしれません。
また、使う側と使われる側が密接に結びつくことで、使われる側の修正が使う側に大きな影響を与えたり、使われる側を他のクラスに変えることが難しくなります。
そこで、クラスを「インタフェース」と「実装」に分けます。
そうすると、使う側はインタフェースを通してのみアクセスすることができ、実装、つまりクラスの中身を隠すことができます
そうすることで、使う側と使われる側とに壁が生まれ、インタフェースを通してのみやりとりできるようになります。
そうすれば、使われる側が不適切な使われ方をされることはなくなりますし、メソッドが仕様通りの結果を返すのであれば修正しても問題ありません。なにより、使われる側はどんなクラスでも構わないため、クラスの交換がしやすくなります。
オブジェクト指向プログラミング
このページで紹介した3つの方法が、オブジェクト指向プログラミングとなります。
オブジェクト指向プログラミングは、簡単に言えばオブジェクト中心。
前ページで紹介した手続き型プログラミングと違い、オブジェクト、つまりインスタンスそれぞれが独立しています。
それぞれのインスタンスがインタフェースを通してメソッドを呼び出し、ポリモーフィズムを使って実際のインスタンスが何クラスか分からなくし、さらに内部はカプセル化で隠しています。
このようにすると、単体テストが簡単にでき、問題が発生した場合の切り分けも容易で、修正しても影響範囲が小さく、さらに使い回しも簡単にできます。
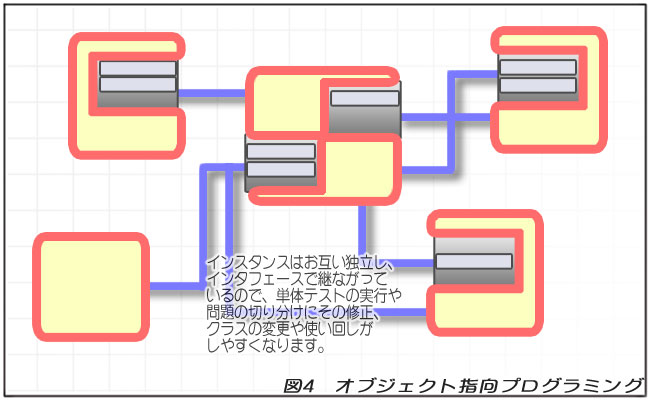
このように、オブジェクト指向プログラミングはメリットだらけです。
一応。